
Definition
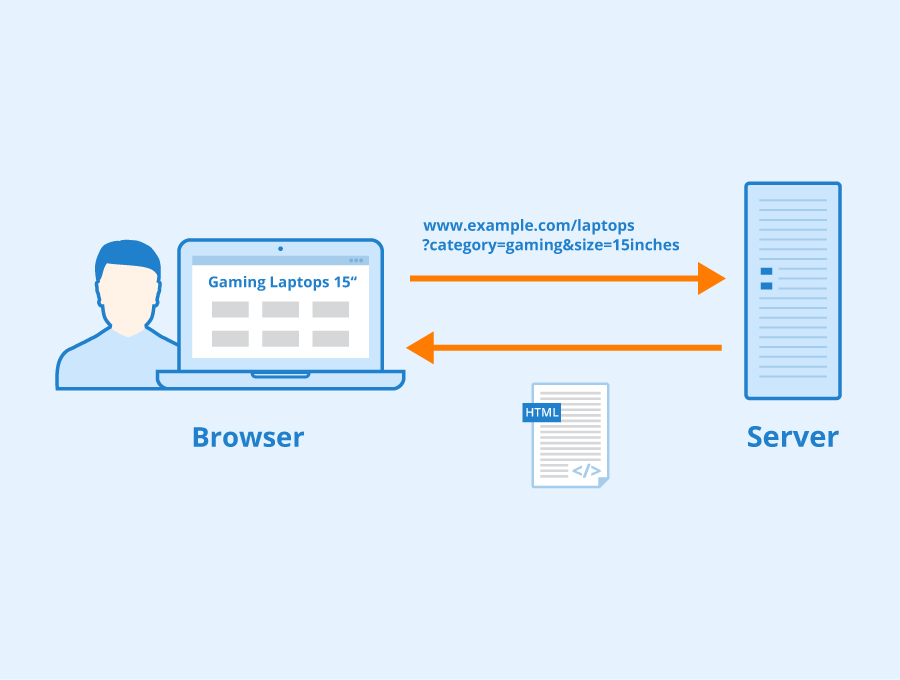
GET parameters (also called URL parameters or query strings) are used when a client, such as a browser, requests a particular resource from a web server using the HTTP protocol.
These parameters are usually name-value pairs, separated by an equals sign =. They can be used for a variety of things, as explained below.
What do URL parameters look like?
An example URL could look like this:
https://www.example.com/index.html?name1=value1&name2=value2
GET parameters always start with a question mark ?. This is followed by the name of the variable and the corresponding value, separated by an =. If an URL contains more than one parameter, they are separated by an Ampersand &.

Screenshot of Zaful.com showing GET parameters.
Using Get Parameters
GET parameters can be divided into active and passive. Active parameters modify the content of a page, for example, by:
- Filtering content:
?type=greendisplays only green products on an e-commerce site. - Sorting contents:
?sort=price_ascendingsorts the displayed products by price, in this case ascending.
Passive GET parameters, on the other hand, do not change a page’s content and are primarily used to collect user data. Application examples are among others:
- Tracking of Session IDs: ?sessionid=12345 This allows visits of individual users to be saved if cookies were rejected.
- Tracking of website traffic:
?utm_source=googleURL parameters can be used to track where your website visitors came from. These UTM (Urchin Tracking Module) parameters work with analytics tools and can help evaluate the success of a campaign. Besidessource, there areutm_medium,utm_campaign,utm_term, andutm_content. More information can be found at Google’s Campaign URL Builder.
Too many subpages with URL parameters can negatively impact a website’s rankings. The most common problems regarding GET parameters are duplicate content, wasted crawl budget, and illegible URLs.
Duplicate content
Generating GET parameters, for example, based on website filter settings, can cause serious problems with duplicate content on e-commerce sites. When shop visitors can use filters to sort or narrow the content on a page, additional URLs are generated. This happens even though the content of the pages does not necessarily differ. The following example illustrates this problem:
One solution to this problem is to uniquely define the relationship between the pages using canonical tags.
Canonical tags indicate to search engines that certain pages should be treated as copies of a particular URL and all ranking properties should be credited to the canonical URL. A canonical tag can be inserted in the <head> area of the HTML document or alternatively in the HTTP header of the web page. If the canonical tag is implemented in the <head> area, the syntax is, for example:
<link rel="canonical" href="https://www.example.com/all-products.html"/>
If this link is added to all URLs that can result from different combinations of filters, the link equity of all these subpages is consolidated on the canonical URL and Google knows which page should be displayed in the SERPs.
Canonical tags are therefore a simple solution to guide search engine crawlers to the content they are supposed to index.
Waste of crawl budget
Google crawls a limited number of URLs per website. This amount of URLs is called crawl budget. More information can be found on the Seobility Blog.
If a website has many crawlable URLs due to the use of URL parameters, Googlebot might spend the crawl budget for the wrong pages. One method to prevent this problem is the robots.txt. This can be used to specify that the Googlebot is not supposed to crawl URLs with certain parameters.
Illegible URLs
Too many parameters within a URL can make it difficult for users to read and remember the URL. Worst case, this can damage usability and click-through rates.
Generally, duplicate content, as well as problems with crawl budget, can be at least partially prevented by avoiding unnecessary parameters in a URL.
Related links
Similar articles
