

To get your web pages ranked on search engine result pages (SERPs), they first need to be crawled and indexed by search engines like Google. However, Google has limited resources and can’t index every page on the internet. This is where the concept of crawl budget comes in.
Crawl budget is the amount of time and resources that Google allocates to crawling and indexing your website. Unfortunately, this crawl budget doesn’t have to match the size of your website. And if you have a large website, this can cause important content to be missed by Google.
The good news is that there are ways to increase the crawl budget available to your website, which we’ll cover in this article. And we will also show you how to efficiently use your existing crawl budget to ensure that Google can easily find and crawl your most important content.
But before we dive in, we’ll start with a quick introduction to how exactly crawl budget works and what types of websites need to optimize their crawl budget.
If you want to skip the theory, you can jump right into crawl budget optimization techniques here!
What is crawl budget?
As mentioned above, crawl budget refers to the amount of time and resources Google invests into crawling your website.
This crawl budget isn’t static though. According to Google Search Central, it is determined by two main factors: crawl rate and crawl demand.
Crawl rate
The crawl rate describes how many connections Googlebot can use simultaneously to crawl your website.
This number can vary depending on how fast your server responds to Google’s requests. If you have a powerful server that can handle Google’s page requests well, Google can increase its crawl rate and crawl more pages of your website at once.
However, if your website takes a long time to deliver the requested content, Google will slow down its crawl rate to avoid overloading your server and causing a poor user experience for visitors browsing your site. As a result, some of your pages may not be crawled or may be deprioritized.
Crawl demand
While crawl rate refers to how many pages of your site Google can crawl, crawl demand reflects how much time Google wants to spend crawling your website. Crawl demand is increased by:
- Content quality: Fresh, valuable content that resonates with users.
- Website popularity: High traffic and powerful backlinks indicate a strong site authority and importance.
- Content updates: Regularly updating content suggests that your site is dynamic, which encourages Google to crawl it more frequently.
Therefore, based on crawl rate and crawl demand, we can say that crawl budget represents the number of URLs Googlebot can crawl (technically) and wants to crawl (content-wise) on your site.
How does crawl budget affect rankings and indexing?
For a page to show up on search results, it needs to be crawled and indexed. During crawling, Google analyzes content and other important elements (meta data, structured data, links, etc.) to understand the page. This information is then used for indexing and ranking.
When your crawl budget hits zero, search engines like Google can no longer crawl your pages completely. This means it takes longer for your pages to be processed and added to the search index. As a result, your content won’t appear on search engine results pages as quickly as it should. This delay can prevent users from finding your content when they search online. In the worst-case scenario, Google might never discover some of your high-quality pages.
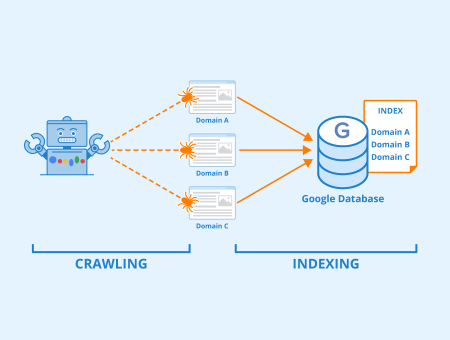
Figure: Indexing – Author: Seobility – License: CC BY-SA 4.0
A depleted crawl budget can also lead to ‘missing content.’ This occurs when Google only partially crawls or indexes your web page, resulting in missing text, links, or images. Since Google didn’t fully crawl your page, it may interpret your content differently than intended, potentially harming your ranking.
It’s important to mention though that crawl budget is not a ranking factor. It only affects the quality of crawling and the time it takes to index and rank your pages on the SERPs.
What types of websites should optimize their crawl budget?
In their Google Search Central guide, Google mentions that crawl budget issues are most relevant to these use cases:
- Website with a large number of pages (1 million+ pages) that are updated regularly
- Websites with a medium to large number of pages (10,000+ pages) that are updated very frequently (daily)
- Websites with a high percentage of pages that are listed as Discovered – currently not indexed in Google Search Console, indicating inefficient crawling*
*Tip: Seobility will also let you know if there’s a large discrepancy between pages that are being crawled and pages that are actually suitable to be indexed, i.e. if there’s a large proportion of pages that are wasting your website’s crawl budget. In this case, Seobility will display a warning in your Tech. & Meta dashboard:
Only X pages that can be indexed by search engines were found.
If your website doesn’t fall into one of these categories, a depleted crawl budget shouldn’t be a major concern.
The only exception is if your site hosts a lot of JavaScript-based pages. In this case you may still want to consider optimizing your crawl budget spending, as processing JS pages is very resource-intensive.
Why does JavaScript crawling easily deplete a website’s crawl budget?
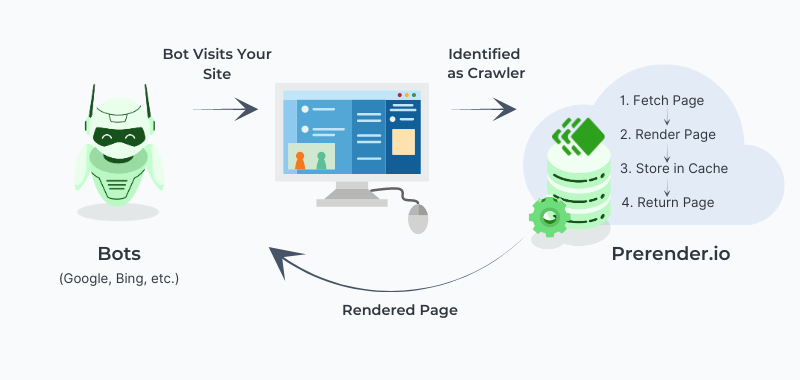
When Google indexes simple HTML pages, it requires two steps: crawl and index. However, for indexing dynamic JavaScript-based content, Google needs three steps: crawl, render, and index. This can be thought of as a ‘two-wave indexing’ approach, as explained in the illustration below.
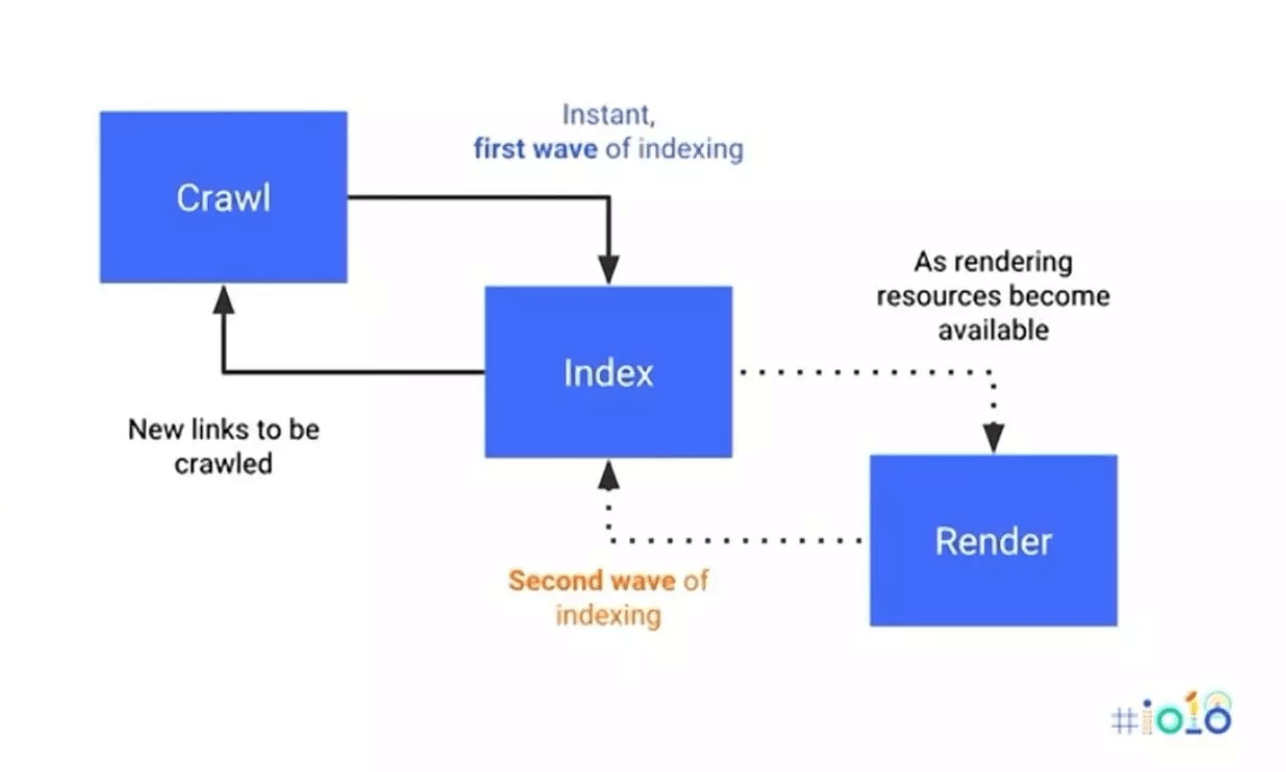
Source: Search Engine Journal
The longer and more complex the process, the more of the site’s crawl budget is used. This additional rendering step can quickly deplete your crawl budget and lead to missing content issues. Often, non-JavaScript web elements are indexed first, before the JavaScript-generated content is fully indexed. As a result, Google may rank the page based on incomplete information, ignoring the partially or entirely uncrawled JavaScript content.
The extra rendering step can also significantly delay the indexation time, causing the page to take days, weeks, or even months to appear on search engine results.
We’ll show you later how to address crawl budget issues specifically on JavaScript-heavy sites. For now, all you need to know is that crawl budget could be an issue if your site contains a lot of JavaScript-based content.
Now let’s take a look at the options you have to optimize your site’s crawl budget in general!
How to optimize your website’s crawl budget
The goal of crawl budget optimization is to maximize Google’s crawling of your pages, ensuring that they are quickly indexed and ranked in search results and that no important pages are missed.
There are two basic mechanisms to achieve this:
- Increase your website’s crawl budget: Improve the factors that can increase your site’s crawl rate and crawl demand, such as your server performance, website popularity, content quality, and content freshness.
- Get the most out of your existing crawl budget: Keep Googlebot from crawling irrelevant pages on your site and direct it to important, high-value content. This will make it easier for Google to find your best content, which in turn might increase its crawl demand.
Next, we will share specific strategies for both of these mechanisms, so let’s dive right in.
Five ways to get the most out of your existing crawl budget
1. Exclude low-value content from crawling
When a search engine crawls low-value content, it wastes your limited crawl budget without benefiting you. Examples of low-value pages include log-in pages, shopping carts, or your privacy policy. These pages are usually not intended to rank in search results, so there’s no need for Google to crawl them.
While it’s not certainly not a big deal if Google crawls a handful of these pages, there are certain cases where a large number of low-value pages are created automatically and uncontrollably, and that’s where you should definitely step in. An example of this are so-called “infinite spaces”. Infinite spaces refer to a part of a website that can generate an unlimited number of URLs. This typically happens with dynamic content that adapts to user choices, such as calendars (e.g., every possible date), search filters (e.g., an endless combination of filters and sorts) or user-generated content (e.g., comments).
Look at the example below. A calendar with a “next month” link on your site can make Google keep following this link infinitely:
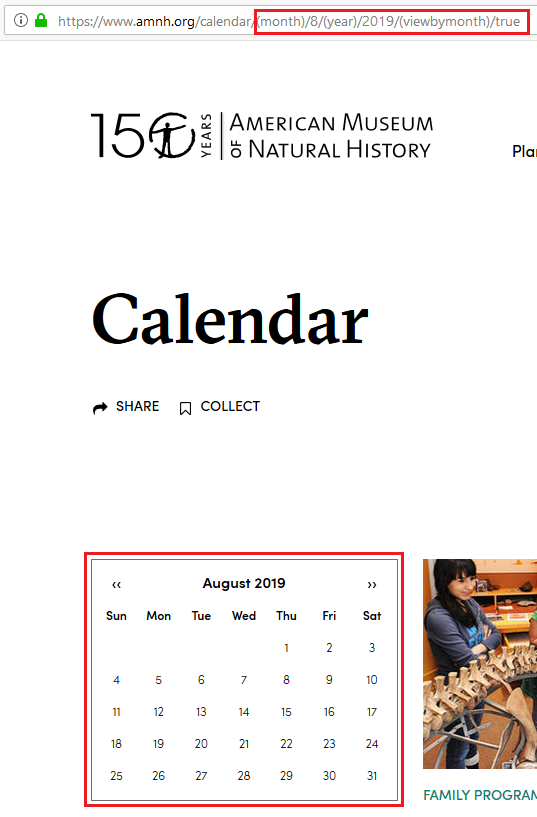
Screenshot of amnh.org
As you can see, each click on the right arrow creates a new URL. Google could follow this link forever, which would create a huge mass of URLs that Google would have to retrieve one by one.
Recommended solution: use robots.txt or ‘nofollow’
The easiest way to keep Googlebot from following infinite spaces is to exclude these areas of your website from crawling in your robots.txt file. This file tells search engines which areas of your website they are allowed or not allowed to crawl.
For instance, if you want to prevent Googlebot from crawling your calendar pages, you only have to include the following directive in your robots.txt file:
Disallow: /calendar/
An alternative method is to use the nofollow attribute for links causing the infinite space. Although many SEOs advise against using ‘nofollow’ for internal links, it is totally fine to use it in a scenario like this.
In the calendar example above, nofollow can be used for the “next month” link to prevent Googlebot from following and crawling it.
2. Eliminate duplicate content
Similar to low-value pages, there’s no need for Google to crawl duplicate content pages, i.e. pages where the same or very similar content appears on multiple URLs. These pages are wasting Google’s resources, because it would have to crawl many URLs without finding new content.
There are certain technical issues that can lead to a large number of duplicate pages and that are worth paying attention to if you’re experiencing crawl budget issues. One of these is missing redirects between the www and non-www versions of a URL, or from HTTP to HTTPS.
Duplicate content due to missing redirects
If these general redirects are not set up correctly, this can cause the number of URLs that can be crawled to double or even quadruple! For example, the page www.example.com could be available under four URLs if no redirect was configured:
https://www.example.com
https://www.example.com
https://example.com
https://example.com
That’s definitely not good for your site’s crawl budget!
Recommended solution: Check your redirects and correct them if necessary
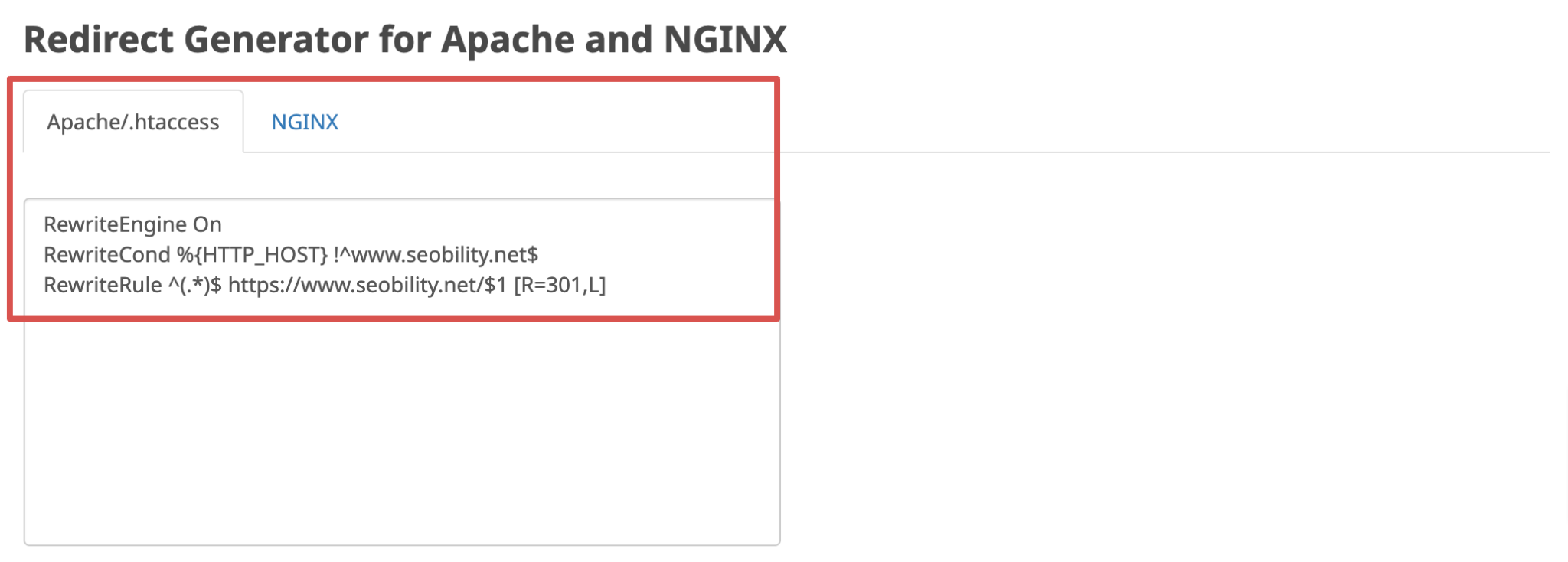
With Seobility’s free Redirect Checker, you can easily if your website’s WWW redirects are configured correctly. Just enter your domain and choose the URL version that your visitors should be redirected to by default:
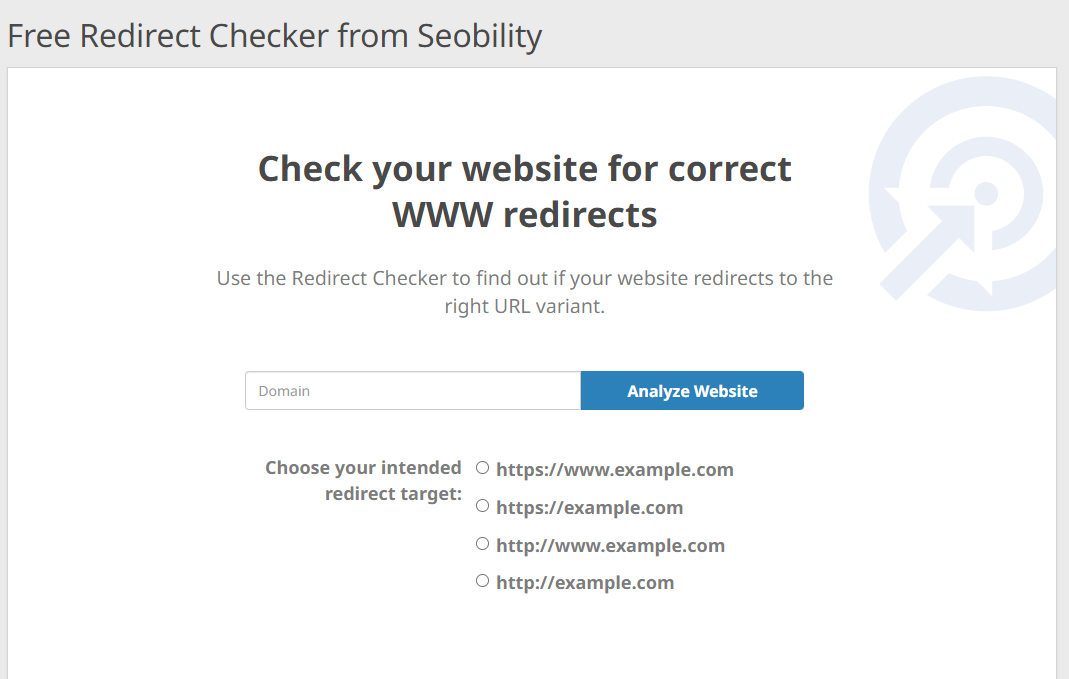
In case the tool detects any issues, you will find the correct redirect code for your Apache or NGINX server in the Redirect Generator on the results page. This way you can correct any broken or missing redirects and resulting duplicate content with just a few clicks.
Duplicate content due to URL parameters
Another technical issue that can lead to the creation of a large number of duplicate pages are URL parameters.
Many eCommerce websites use URL parameters to let visitors sort the products on a category page by different metrics such as price, relevance, reviews, etc.
For example, an eCommerce site might append the parameter ?sort=price_asc to the URL of its product overview page to sort products by price, starting with the lowest price:
www.abc.com/products?sort=price_asc
This would create a new URL containing the same products as the regular page, just sorted in a different order. For sites with a large number of categories and multiple sorting options, this can easily add up to a significant number of duplicate pages that waste crawl budget.
A similar problem occurs with faceted navigation, which allows users to narrow the results on a product category page based on criteria such as color or size. This is done by adding URL parameters to the corresponding URL:
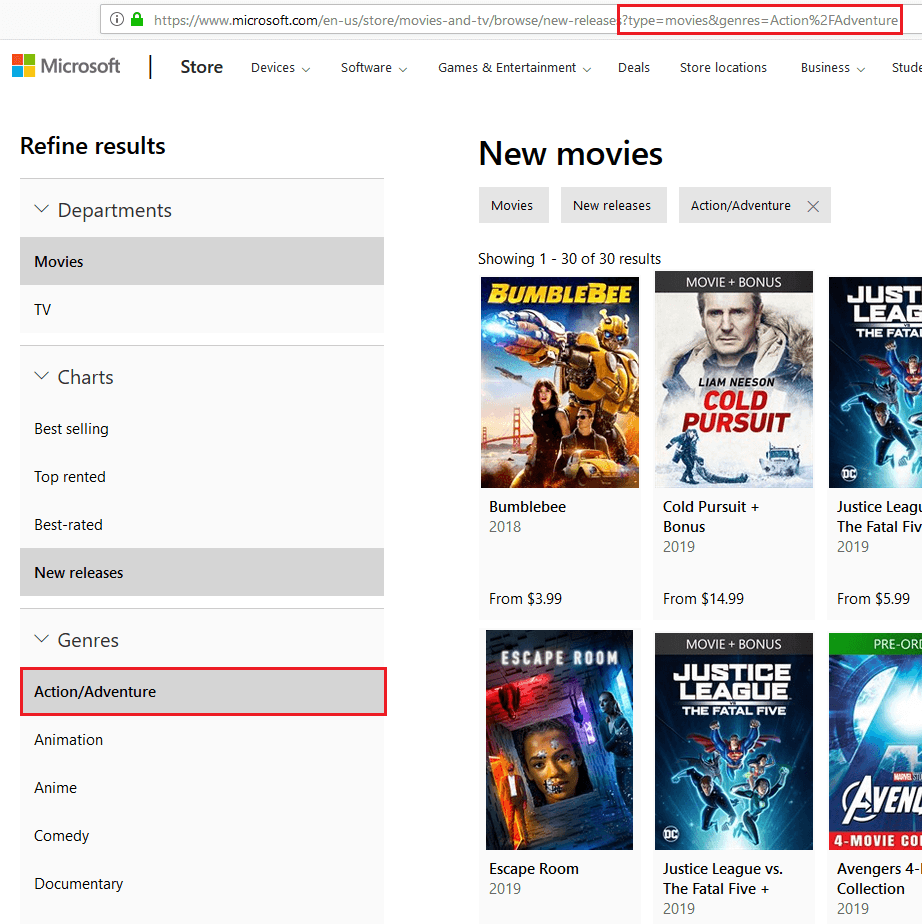
Screenshot from microsoft.com
In the example above, the results are limited to the Action/Adventure genre by adding the URL parameter &genres=Action%2FAdventure to the URL. This creates a new URL that wastes the crawl budget because the page does not provide any new content, just a snippet of the original page.
Recommended solution: robots.txt
As with low-value pages, the easiest way to keep Googlebot away from these parameterized URLs is to exclude them from crawling in your robots.txt file. In the examples above, we could disallow the parameters that we don’t want Google to crawl like this:
Disallow: /*?sort=
Disallow: /*&genres=Action%2FAdventure
Disallow: /*?genres=Action%2FAdventure
This approach is the easiest way to deal with crawl budget issues caused by URL parameters, but keep in mind that it’s not the right solution for every situation. An important downside of this method is that if pages are excluded from crawling via robots.txt, Google will no longer be able to find important meta information such as canonical tags on them, preventing Google from consolidating the ranking signals of the affected pages.
So if crawl budget is not your primary concern, another method of handling parameters and faceted navigation may be more appropriate for your individual situation.
You can find in-depth guides on both topics here:
You should also avoid using URL parameters in general, unless they are absolutely necessary. For example, you should no longer use URL parameters with session IDs. It’s better to use cookies to transfer session information.
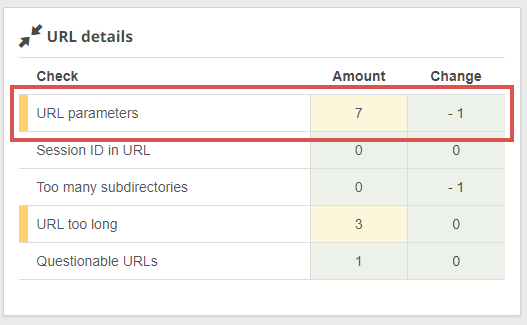
Tip: With Seobility’s Website Audit, you can easily find any URLs with parameters on your website.
Seobility > Onpage > Tech. & Meta > URL details
Now you should have a good understanding of how to handle different types of low-value or duplicate pages to prevent them from draining your crawl budget. Let’s move on to the next strategy!
3. Optimize resources, such as CSS and JavaScript files
As with HTML pages, every CSS and JavaScript file on your website must be accessed and crawled by Google, consuming part of your crawl budget. This process also increases page loading time, which can negatively affect your rankings since page speed is an official Google ranking factor.
Recommended solution: Minize the number of files and/or implement a prerendering solution
Keep the number of files you use to a minimum by combining your CSS or JavaScript code into fewer files, and optimize the files you have by removing unnecessary code.
However, if you website uses a large amount of JavaScript, this may not be enough and you might want to consider implementing a pre-rendering solution.
In simple terms, prerendering is the process of turning your JavaScript content into its HTML version, making it 100% index-ready. As a result, you cut the indexing time, use less crawl budget, and get all your content and its SEO elements perfectly indexed.
Prerender offers a prerendering solution that can significantly accelerate your JavaScript website’s indexing speed by up to 260%.
You can learn more about prerendering and its benefits to your website’s JavaScript SEO here.
4. Avoid links to redirects and redirect loops
If URL A redirects to URL B, Google has to request two URLs from your web server before it gets to the actual content it wants to crawl. And if you have a lot of redirects on your site, this can easily add up and drain your crawl budget.
The situation is even worse with redirect loops. Redirect loops refer to an infinite loop between pages: Page A > Page B > Page C > and back to Page A, trapping Googlebot and costing your precious crawl budget.
Recommended solution: Link directly to the destination URL and avoid redirect chains
Instead of sending Google to a page that redirects to another URL, you should always link to the actual destination URL when using internal links.
Fortunately, Seobility can display all the redirecting pages on your site, so you can easily adjust the links that currently point to redirecting pages:
Seobility > Onpage > Structure > Links
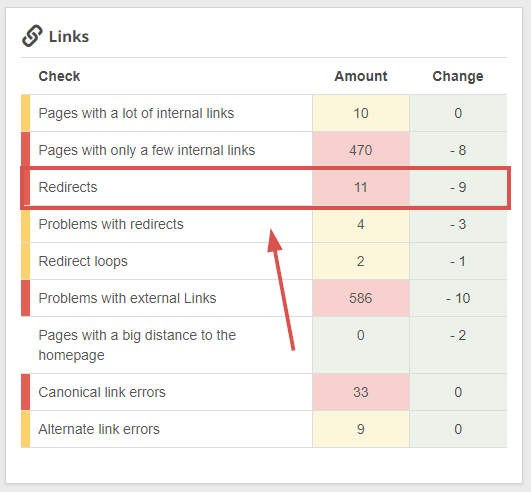
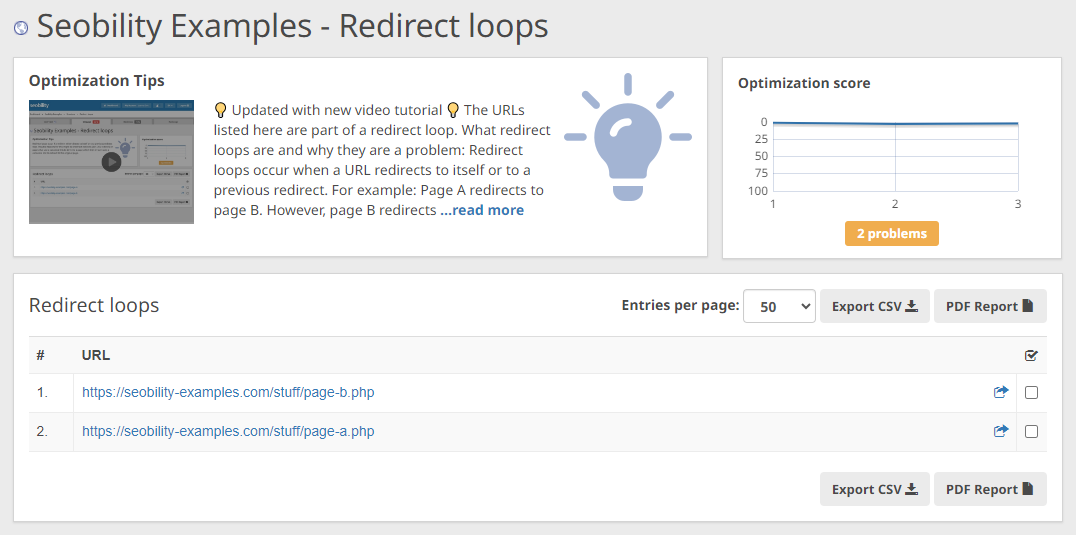
And with the “redirect loops” analysis, you can see at a glance if there are any pages that are part of an infinite redirect cycle.
Seobility > Onpage > Structure > Links > Redirect loops
5. Avoid soft 404 error pages
Web pages come and go. After they have been deleted, sometimes users and Google still request them. When this happens, the server should respond with a “404 Not Found” status code (indicating that the page doesn’t exist).
However, due to some technical reasons (e.g. custom error handling or CMS internal system settings) or the generation of dynamic JS content, the server may return a “200 OK” status code (indicating that the page exists). This condition is known as a soft 404 error.
This mishandling signals Google that the page does exist and will keep crawling it until the error is fixed – costing you your valuable crawl budget.
Recommended solution: Configure your server to return an appropriate status code
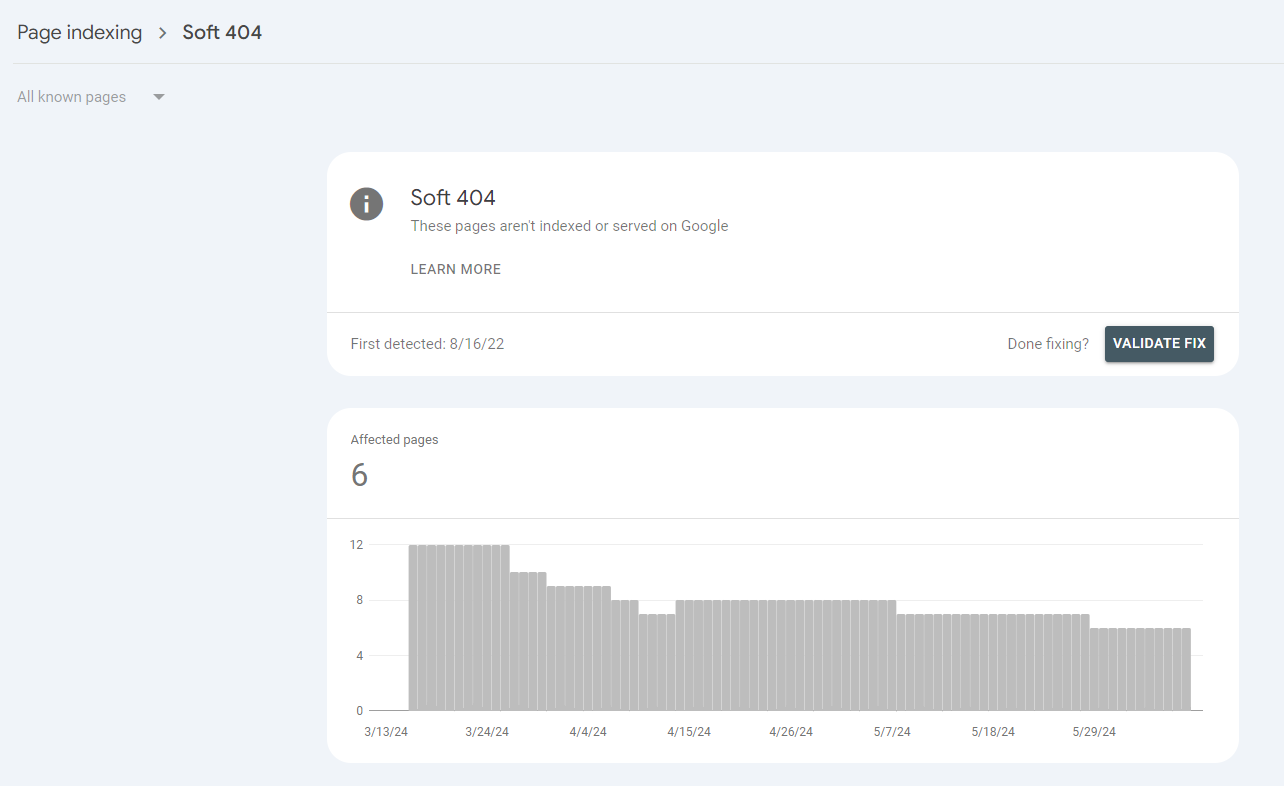
Google will let you know of any soft 404 errors on your website in Search Console:
Google Search Console > Page indexing > Soft 404s
To get rid of soft 404 errors, you basically have three options:
- If the content of the page no longer exists, you should make sure that your server returns a 404 status code.
- If the content has been moved to a different location, you should redirect the page with a 301 redirect and replace any internal links to point to the new URL.
- If the page is incorrectly categorized as a soft 404 page (e.g. because of thin content), improving the quality of the page content may resolve the error.
For more details, check out our wiki article on soft 404 errors.
6. Make it easy for Google to find your high-quality content
To further maximize your crawl budget, you should not only keep Googlebot away from low-quality or irrelevant content, but also guide it toward your high-quality content. The most important elements to help you achieve this are:
- XML sitemaps
- Internal links
- Flat site architecture
Provide an XML sitemap
An XML sitemap provides Google with a clear overview of your website’s content and is a great way to tell Google which pages you want crawled and indexed. This speeds up crawling and reduces the likelihood that high-quality and important content will go undetected.
Use internal links strategically
Since search engine bots navigate websites by following internal links, you can use them strategically to direct crawlers to specific pages. This is especially helpful for pages that you want to be crawled more frequently. For example, by linking to these pages from pages with strong backlinks and high traffic, you can ensure that they are crawled more often.
We also recommend that you link important sub-pages widely throughout your site to signal their relevance to Google. Also, these pages should not be too far away from your homepage.
Check out this guide on how to optimize your website’s internal links for more details on how to implement these tips.
Use a flat site architecture
Flat site architecture means that all subpages of your website should be no more than 4 to 5 clicks away from your homepage. This helps Googlebot to understand the structure of your website and saves your crawl budget from complicated crawling.
With Seobility, you can easily analyze the click distance of your pages:
Seobility > Onpage > Structure > Page levels
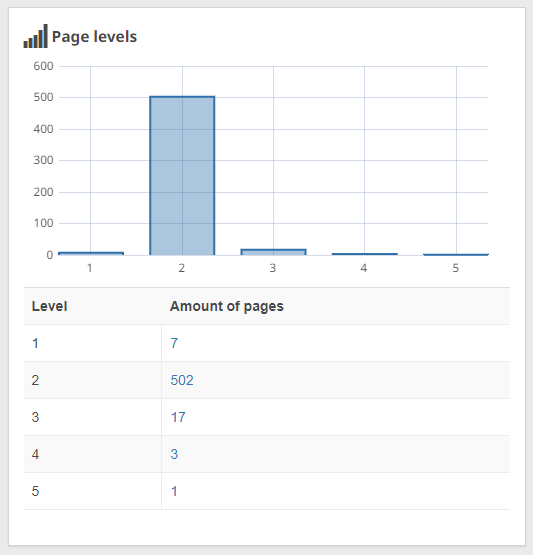
If any of your important pages are more than 5 clicks away from your homepage, you should try to find a place to link to them at a higher level so that they won’t be overlooked by Google.
Two ways to increase your crawl budget
So far we’ve focused on ways to get the most out of your existing crawl budget but as we’ve mentioned in the beginning, there are also ways to increase the total crawl budget that Google assigns to your website.
As a reminder, there are two basic factors that determine your crawl budget: crawl rate and crawl demand. So if you want to increase your website’s overall crawl budget, these are the two main factors you can work on.
Increasing the crawl rate
Crawl rate is highly dependent on your server performance and response time. In general, the higher your server performance and the faster its response time, the more likely Google is to increase its crawl rate.
However, this will only happen if there’s sufficient crawl demand. Improving your server performance is useless if Google doesn’t want to crawl your content.
If you can’t upgrade your server, there are several on-page techniques you can implement to reduce the load on your server. These include implementing caching, optimizing and lazy-loading your images, and enabling GZip compression.
This server optimization guide explains how to implement these tips as well as many other techniques to improve your server response times and page speed in general.
Increasing crawl demand
While you can’t actively control how many pages Google wants to crawl, there are a few things you can do to increase the chances that Google will want to spend more time on your website:
- Avoid thin or spammy content. Instead, focus on providing high-quality, valuable content.
- Implement the strategies we’ve outlined above to maximize your crawl budget. By ensuring that Google only encounters relevant, high-quality content, you create an environment where the search engine recognizes the value of your site and prioritizes crawling it more frequently. This signals to Google that your site is worth exploring in greater depth, ultimately increasing crawl demand.
- Build strong backlinks, increase user engagement, and share your pages on social media. These will help increase your website’s popularity and generate genuine interest.
- Keep your content fresh, as Google prioritizes the most current and high-quality content for its users.
At this point, you should be equipped with a large arsenal of strategies to help you get rid of any crawl budget problems on your site. Finally, we’ll leave you with some tips on how to monitor the progress of your crawl budget optimization.
How to monitor your crawl budget optimization progress
Like many SEO tasks, crawl budget optimization isn’t a one-day process. It requires regular monitoring and fine-tuning to ensure that Google easily finds the important pages of your site.
The following reports can help you keep an eye on how your site is being crawled by Google.
Crawl stats in Google Search Console
In this report, you can see the number of pages crawled per day for your site over the past 90 days.
Settings > Crawl Stats > Open report
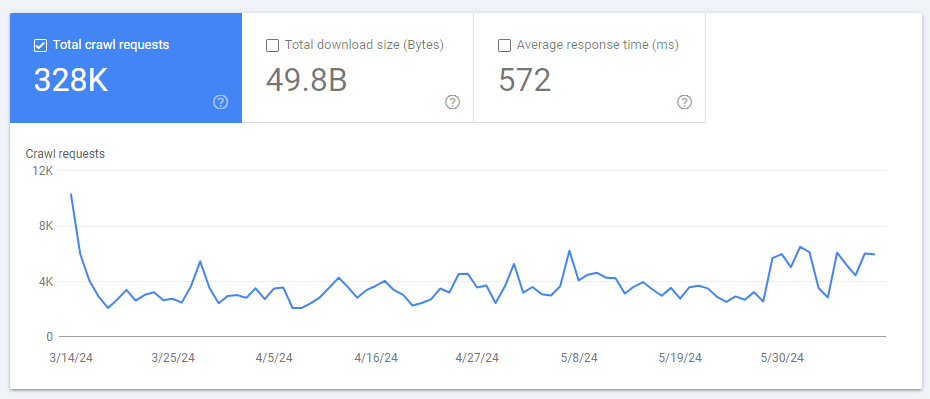
A sudden drop in crawl requests can indicate problems that are preventing Google from successfully crawling your site. On the other hand, if your optimization efforts are successful, you should see an increase in crawl requests.
However, you should be cautious if you see a very sudden spike in crawl requests! This could signal new problems, such as infinite loops or massive amounts of spam content created by a hacker attack on your site. In these cases, Google needs to crawl many new URLs.
In order to determine the exact cause of a sudden increase in this metric, it is a good idea to analyze your server log files.
Log file analysis
Web servers use log files to track each visit to your website, storing information like IP address, user agent, etc. By analyzing your log files, you can find out which pages Googlebot crawls more frequently and whether they are the right (i.e., relevant) pages. In addition, you can find out if there are some pages that are very important from your point of view, but that are not being crawled by Google at all.
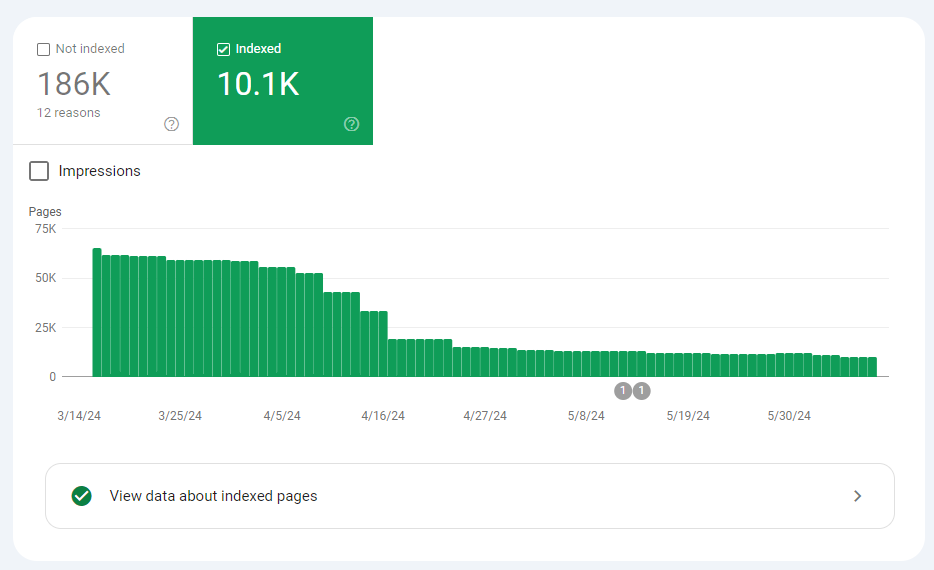
Index coverage report
This report in Search Console shows you how many pages of your website are actually indexed by Google, and the exact reasons why the other pages are not.
Google Search Console > Indexing > Pages
Optimize your crawl budget for healthier SEO performance
Depending on the size of your website, crawl budget can play a critical role in the ranking of your content. Without proper management, search engines may struggle to index your content, potentially wasting your efforts in creating high-quality content.
Additionally, the impact of poor crawl budget management is amplified for JavaScript-based websites, as dynamic JS content requires more crawl budget for indexing. Therefore, relying solely on Google to index your content can prevent you from realizing your site’s true SEO potential.
If you have any questions, feel free to leave them in the comments!



