
Definition
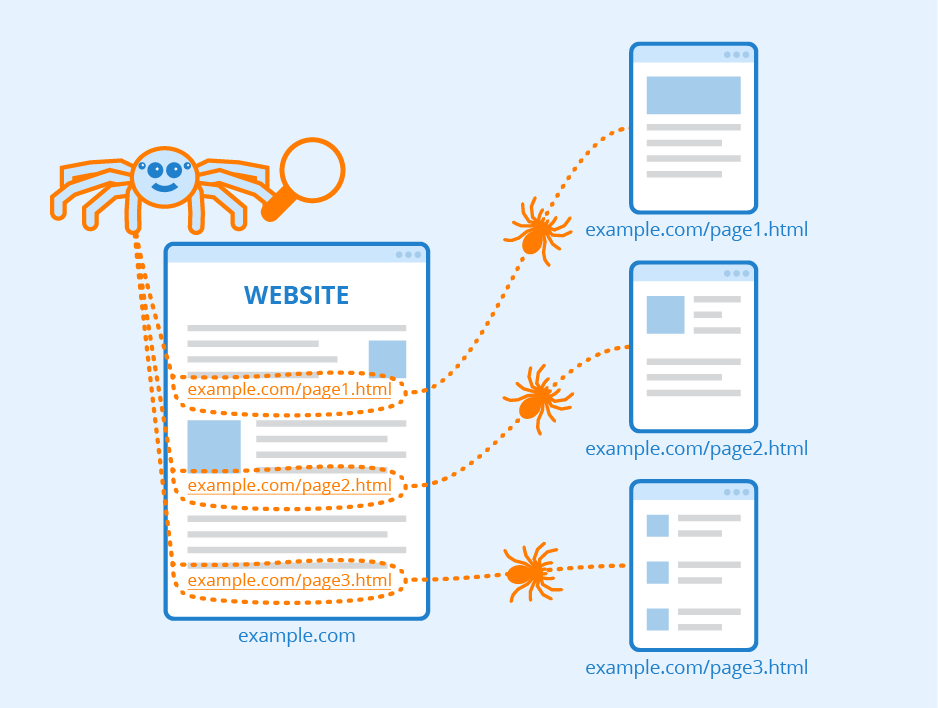
A crawler is a piece of software that searches the internet and analyzes its contents. It is mainly used by search engines to index websites. In addition, web crawlers are also used for data collection (e.g. for web feeds or, especially in marketing, e-mail addresses). Crawlers are bots, i.e. programs that automatically perform defined, repetitive tasks. The first web crawler was called World Wide Web Wanderer and was used in 1993 to measure the growth of the internet. A year later, the first internet search engine was launched under the name Webcrawler, giving this type of program its name. Today, such bots are the main reason why search engine optimization (SEO) is at the forefront of internet-based marketing. For successful SEO, you should, therefore, know how these programs work. This will be explained in greater detail below.
Functioning of Web Crawlers
A crawler finds new web pages just like a user while surfing the internet through hyperlinks. When it retrieves a page, it saves all the URLs it contains. The crawler then opens each of the saved URLs one by one to repeat the process: It analyses and saves further URLs. This way, search engines use bots to find linked pages on the web. In most cases, however, not all URLs are processed by the crawler but are limited by a selection. At some point, the process is stopped and restarted. The collected information is usually evaluated and stored via indexing so that it can be found quickly.
Commands to Web Crawlers
You can use the Robots Exclusion Standards to tell crawlers which pages of your website are to be indexed and which are not. These instructions are placed in a file called robots.txt or can also be communicated via meta tags in the HTML header. Note, however, that crawlers do not always follow these instructions.
Usage Scenarios of Crawler Solutions
Crawlers find a wide range of applications and are often offered as a function of a software package. In addition to indexing the web, which is relevant for search engines, the programs can also be used to collect thematically focused information. If the crawler’s search is limited by classifying a website or a link, only thematically relevant pages can be found on the web. In addition, crawlers can be used for data mining and webometrics. In data mining, bots collect information from large databases to identify trends and cross-references. By using bots, relevant databases can be created and evaluated. Webometry, on the other hand, deals with the investigation of the internet in terms of content, properties, structures, and user behavior.
Harvesters are a special type of web crawler. This term refers to programs that search the web for email addresses and “harvest” them, i.e. store them on a list for activities such as marketing or sending spam.
Optimization of a Website’s Crawlability for SEO
Crawlability SEO Checker
Check the crawlability of your web page
In order to achieve maximum crawlability and the best possible SEO result, a website should have good internal linking. Bots follow links to analyze new web pages and content. An SEO friendly linking ensures that all important subpages can be found by search bots. If high-quality content is discovered on one of these pages, a high ranking is likely.
XML or HTML sitemaps are also a common solution to make the work of crawlers easier. They contain the complete link structure of a website so that a search engine can easily find and index all subpages.
You also shouldn’t underestimate the correct use of HTML tags for SEO. By consistently using these structures, you can help bots interpret the content of a page correctly. This includes, for example, the standard use of headings (h1, h2, h3, etc.), link titles (title) and image descriptions (alt).
Furthermore, you should not use Java or Flash content. Although Google is now able to crawl JavaScript pages, it still takes a lot of crawling budget. Instead, you should use server-side languages such as PHP or ASP to generate navigation elements and other components of the website in HTML. The client (web browser or bot) does not need a plugin to understand and index HTML results.
In addition, a modern website should no longer be based on frames but should solve all design aspects with CSS. Pages that still use frames today are only partially indexed and misinterpreted by search engines.
Another important aspect regarding the optimization of crawlability for SEO is that pages that should be indexed must not be excluded from crawling in robots.txt or contain a “noindex” directive in the robots meta tag. In order to check whether this is the case, you can use various tools from the search engine providers. Google, for example, provides the Search Console for this purpose.
Since cybercriminals increasingly initiate bot attacks, website operators use so-called bot protection. This security system monitors site traffic, detects bots and blocks them if necessary. However, incorrectly configured bot protection can also block bots from Google, Bing and other search engines, which means that these can no longer index your web pages. Therefore, you should make sure that bot protection checks the IP address of the host before blocking it. This way, it is detected, whether the bot belongs to Google, Bing or other search engines.
Finally, you should note that crawlability is also influenced by the performance of a website. If your website is located on a slow server or is slowed down by technical problems, it usually does not receive a good search engine ranking. Some of the subpages are probably not indexed at all because bots jump off when a page loads for too long. Therefore, a fast infrastructure is the basis for effective SEO.
In the following, we have summarized the points just explained in the form of a short checklist for you:
- good internal linking
- XML or HTML sitemap
- correct use of HTML tags for SEO
- no Java or Flash content
- no frames
- checking the pages excluded by robots.txt and “noindex”
- correct configuration of bot protection
- fast performance for effective SEO
Related links
- https://www.searchenginejournal.com/anatomy-of-a-search-engine-crawler/2230/
- https://www.google.com/search/howsearchworks/crawling-indexing/
