
¿Qué son los parámetros GET?
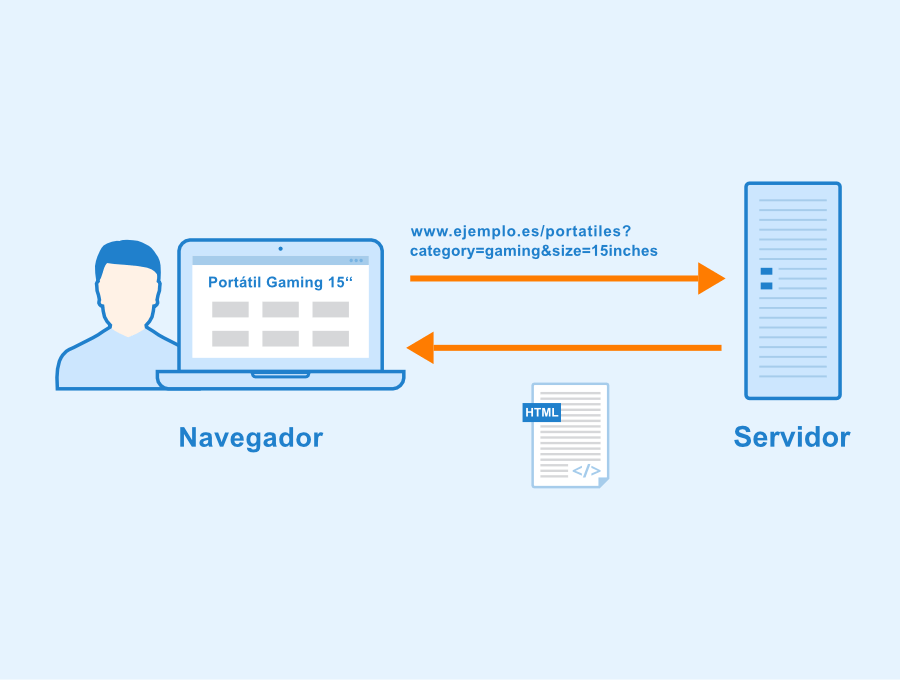
Los parámetros GET se usan cuando un cliente, como un navegador, solicita un recurso particular de un servidor web usando el protocolo HTTP.
Otras formas de denominar dichos parámetros en español son parámetros URL, cadenas de consulta, y en menor medida, GET parameters.
Estos parámetros suelen nombrarse en conjuntos pares separados por un signo de igual =. Se pueden utilizar para una gran variedad de propósitos, como explicaremos a continuación.
¿Qué aspecto tienen los parámetros URL?
Una dirección de ejemplo podría verse de esta manera:
https://www.ejemplo.com/index.html?nombre-1=valor-1&nombre-2=valor2
Los parámetros GET siempre inician con un signo de interrogación ?. A este le siguen el nombre de la variable y su valor correspondiente, separados por un =. Si una dirección contiene más de un parámetro, estos se separan por un “et”, conocido en inglés como ampersand &.

Captura de pantalla de Zalando.es mostrando algunos parámetros GET.
Uso de los Parámetros Get
Los parámetros GET se pueden dividir en dos categorías, activos y pasivos. Los parámetros activos modifican el contenido de una página, como por ejemplo:
- Filtrar contenido:
?type=greensólo mostraría productos ecológicos dentro de un sitio web estilo e-commerce. - Ordenar contenido:
?sort=price_ascendingOrdena y muestra productos por precio, en este caso, de manera ascendente.
Por otro lado, los parámetros GET pasivos no cambian el contenido de una página. Estos se utilizan principalmente para recopilar datos del usuario o de la usuaria. Algunos ejemplos de su aplicación serían:
- Seguimiento de las Session IDs: ?sessionid=12345 Esto permite guardar las visitas de los/las usuarios/as en caso de que se rechacen las cookies.
- Seguimiento del tráfico web:
?utm_source=googleLas cadenas de consulta se pueden usar para rastrear de dónde vienen los y las visitantes de tu sitio. Este parámetro UTM (módulo de seguimiento Urchin) funciona con herramientas analíticas que ayudan a evaluar el éxito de una campaña. Además desource, también existenutm_medium,utm_campaign,utm_termyutm_content. Puedes encontrar más información en la página de Google Campaign URL Builder (Creador de URL de campaña).
Problemas potenciales relacionados con los parámetros GET
Demasiadas subpáginas con cadenas de consulta pueden incidir de forma negativa en el posicionamiento del sitio web. Los problemas más comunes relacionados con los parámetros GET son contenido duplicado, desperdicio de crawl budget y URLs ilegibles.
Contenido duplicado
Generar cadenas de consulta en función de la configuración de filtros de un sitio puede causar grandes problemas. Cuando los/las usuarios/as pueden emplear filtros para ordenar o limitar el contenido de una página, se generan URLs adicionales.
En los sitios web estilo e-commerce, por ejemplo, lo antes señalado puede producir accidentalmente gran cantidad de contenido duplicado. Esto ocurre a pesar de que el contenido de las páginas no difiera. A continuación, te mostramos un ejemplo que ilustra el problema:
Una solución podría ser definir de forma única la relación entre las páginas a través de URLs canónicas. Las URL canónicas le indican a los buscadores que ciertas páginas deben tratarse como copias de una dirección particular. De esta manera, todas las propiedades de clasificación se acreditan a la URL canónica y no a sus variantes.
Una URL canónica se puede insertar en el área <head> de un documento HTML. Alternativamente, puede insertarse también en el HTTP header de una página web. Al insertarla en el área <head>, por ejemplo, la sintaxis correcta sería:
<link rel="canonical" href="https://www.ejemplo.com/todos-los-productos.html"/>
Debes añadir esto a todos los posibles enlaces resultantes de diferentes combinaciones de filtros. Así, el link juice de todas estas subpáginas se concentrará en la URL canónica. De esta manera, te aseguras que Google comprenda qué página mostrar en sus hojas de resultados (SERPs).
Las URL canónicas son una solución sencilla para dirigir a las arañas web al contenido que deben indexar.
Desperdicio de crawl budget
Google rastrea un número limitado de direcciones por cada sitio. Esta cantidad de URLs suele llamarse crawl budget, que se traduce al español como presupuesto de rastreo. Puedes obtener más detalles en Seobility Blog (en inglés).
Si tu sitio usa muchos parámetros GET de manera incorrecta, Google bot podría agotar el crawl budget en los enlaces equivocados. Un método para prevenir este problema es usar el robots.txt. Con él, puedes especificar a Google bot que no rastree e indexe enlaces con ciertos parámetros.
URLs ilegibles
Demasiadas cadenas de consulta en una dirección pueden dificultar la lectura a los y las visitantes de tu web. En el peor de los casos, esto puede perjudicar la usabilidad y el click-through rate del sitio.
Generalmente, el contenido duplicado y los problemas de crawl budget se pueden prevenir parcialmente evitando emplear parámetros GET innecesarios.
Ampliar conocimientos

{kind=link}