


Duplicate content is a common issue for website owners and SEO professionals. It can lead to a myriad of problems, including reduced search engine visibility, diluted link equity and a frustrating user experience.
Despite the name, your company’s content director isn’t usually the right person to fix this. Instead, duplicate content is typically a technical problem that requires a technical approach to fix.
In this blog post, we’ll explore the common causes of duplicate content issues and, most importantly, provide you with actionable strategies and solutions for solving these challenges!
- Duplicate Content Defined
- What Is the Impact of Duplicate Content on SEO?
- Common Causes of Duplicate Content
- Poor Content Management
- Incorrect Server Configuration
- Multi-Language Management Issues
- Product Pages on eCommerce Websites
- Pagination
- Tags, Categories and Author Archives on WordPress Websites
- How to Discover Duplicate Content
- Monitor and Audit Your Content Performance
Duplicate Content Defined
Before we dig too deep into this topic, it’s best to define what “duplicate content” means in the context of this article. Put simply, the term duplicate content refers to the occurrence of one and the same piece of content or very similar content under several URLs.
While it can be used to describe identical content on different domains, in this article we’re interested in what you can do about it when it occurs within one website – also known as “internal duplicate content”.
I’ll be talking about substantial blocks of content that either completely match other content on the same site or are very similar.
Essentially, it’s when the same or very similar content appears at more than one web address (URL).
What Is the Impact of Duplicate Content on SEO?
Google very clearly tells us that they “try hard to index and show pages with distinct information.”
“Our users typically want to see a diverse cross-section of unique content when they do searches. In contrast, they’re understandably annoyed when they see substantially the same content within a set of search results.”
While any good SEO should read between the lines from Google, they have consistently emphasized the importance of unique content, and we should pay attention.
If individual pages on your website struggle to provide unique information, you’re going to struggle to win those top positions in the SERPs.
Websites with duplicate content suffer from reduced organic search traffic and fewer indexed pages, and in cases of manipulation, they run the risk of an algorithmic penalty. This is for a few reasons:
-
- Remember that Googlebot isn’t a human. If it discovers 2 or more pages with the same content, the algorithm then needs to decide which page to rank. Though they can get this right, they can also get it wrong.

Figure: Duplicate Content – Author: Seobility – License: CC BY-SA 4.0
- Spreading content across multiple URLs also spreads positive ‘signals’ such as backlinks, social shares and engagement statistics. In this way, each individual URL benefits less from these signals than a single URL would.
- Duplicate content requires Googlebot to spend more time and resources on crawling your website, even though there’s no benefit for them to do so. You’re effectively wasting their time (and your website’s crawl budget).
SEO already involves many factors that are out of our control, so it seems short-sighted to present a confusing mess of content to Google and leave it up to them to sort out.
If you’re invited to an interview for a job you really want, do you arrive in dirty clothes, unprepared? Anyone who truly wants the position is well presented and thoroughly researched ahead of time.
Organic search is only becoming more and more competitive, so we want to do the same and present the absolute best, clearest version of our website to Google so they fully understand it.
Common Causes of Duplicate Content
Duplicate content issues can arise from a variety of reasons. Different types of websites such as blogs, eCommerce websites etc. all come with a unique set of characteristics that can lead to duplicate content.
Below, I’ll walk you through some of the most common causes of duplicate content that I see while performing technical SEO audits on all types of client sites. I’ll then walk you through how to fix these issues if you discover them on your own website!
Poor Content Management
While there are absolutely many technical issues that cause duplicate content, I would be remiss not to mention checking in with your content manager first.
Literally Duplicated Content
Usually, when I first take a look at a website, one of the first things I’ll discover is low-value, duplicate pages with URLs like:
- https://example.com/test-page/
- https://example.com/test-page-1/
- https://example.com/test-page-2/
Often, people intentionally duplicate content to make it easier to create new pages with a similar layout.
This is fine; the problem is that they forget to clean up.
Source: https://ofm.od.nih.gov/
The good news is these are easily fixed by simply deleting the pages and serving either a 404 or 410 status code. But before you do this, make sure that there are no internal links on your website that point to these pages, to avoid broken links later on. If you’re using Seobility, you can easily check this by searching for the URL you want to delete in the “Check a specific URL” search box:
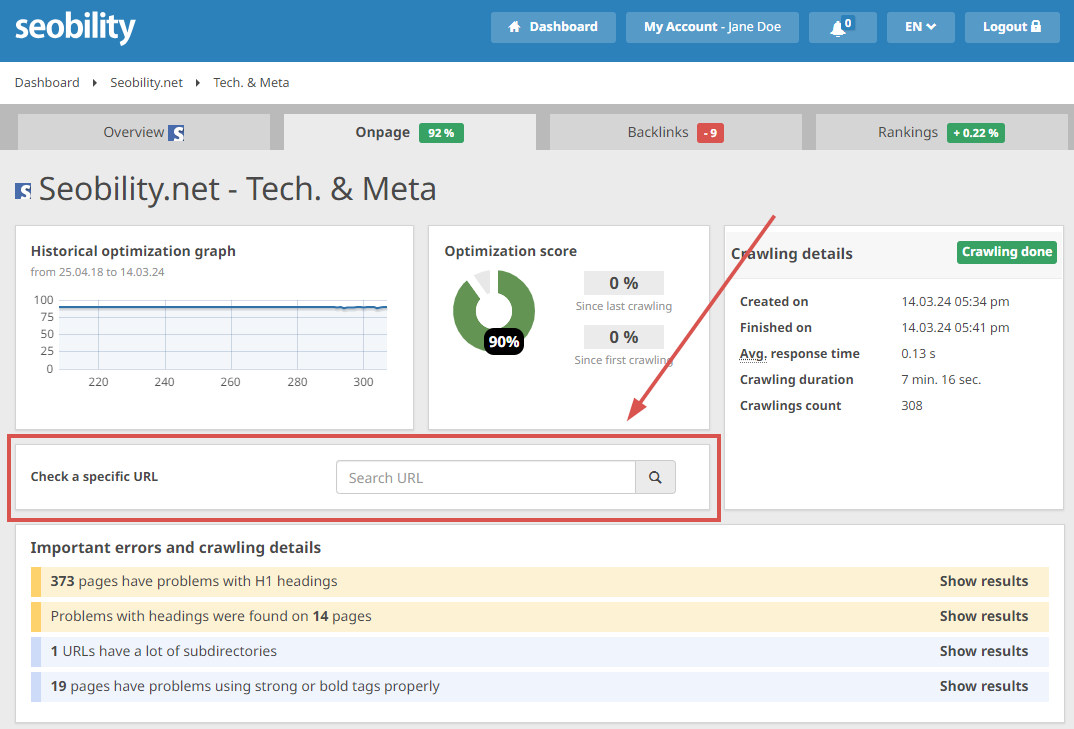
Then navigate to the “Links” tab, to see all incoming links to that page:
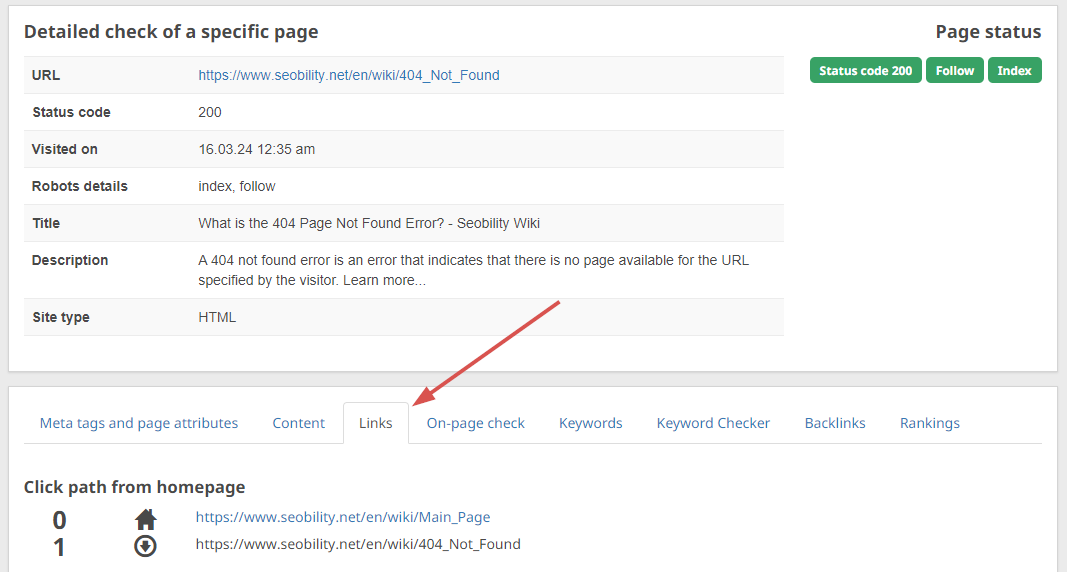
Duplicated Landing Pages
Many clients I work with are growing their organic search channels while running paid search and Facebook ads. To make it easy to generate landing pages for their ads, they quickly duplicate existing pages.
It’s very common to see the following:
- https://example.com/service/
- https://example.com/service-lp-facebook/
- https://example.com/service-lp-googleads/
While some of the copy used on these pages is different from the original, typically the title, meta description, and 90% of the text are identical.
In this scenario, the client wants to rank their /service/ page in Google, so we really want to be clear in the message we’re sending to Google.
Any landing pages used for other sources of traffic can use the noindex directive, so they won’t be listed in Google’s index and won’t compete with pages that are “made for organic search.”
The exception to this rule is if we expect those other landing pages to earn social shares or backlinks. In this case, you can keep the page indexable and set the canonical URL on all landing pages to the main /service/ page instead.
The canonical URL tells Google that the main /service/ page is the “original” source of the content that should be displayed in the search results. It will also consolidate the positive signals coming from backlinks to the canonical page.
In the example above, we would need to add this canonical tag to all of the duplicated landing pages:
<link rel="canonical" href="https://example.com/service/" />
If you use this method, remember that a page shouldn’t be noindexed while pointing to a different canonical URL, to avoid sending mixed signals to Google.
Google search advocate John Mueller confirms this:
“…you shouldn’t mix noindex & rel=canonical…they’re very contradictory pieces of information for us. We’ll generally pick the rel=canonical and use that over the noindex, but any time you rely on interpretation by a computer script, you reduce the weight of your input.”
Incorrect Server Configuration
Google officially announced that HTTPS was a ranking factor back in 2014, and in 2018, Google Chrome began marking web pages loaded over HTTP as “not secure”.
All websites should be secured, which is explained in more detail in this guide on switching from HTTP to HTTPS.
For many sites served over HTTPS however, an all too common cause of duplication comes from a lack of redirects, which allows the same piece of content to be viewed at 2 or more URLs.
In simple terms, if your website is accessible through both HTTP and HTTPS, with no redirects between the two versions, this will result in duplicate content. And not just for one page, but for all the sub-pages on your entire website!
Your website shouldn’t be available at https://example.com and https://example.com.
Similarly, it shouldn’t be available on a subdomain as well as the root domain, such as https://www.example.com and https://example.com.
But even if you have your domain handling sorted out, there are other culprits that can lead to duplication issues, such as a simple trailing slash being attached to your URLs. https://example.com/service shouldn’t be available at https://example.com/service/, and vice-versa.
For all of these scenarios, it’s important to have redirects in place that automatically redirect visitors to your one preferred URL variant. This should always be the HTTPS version to provide a secure connection for all website visitors. From there, you’ll need to decide how to set up your subdomains (www or non-www in most cases) and permalinks (with or without a trailing slash).
My preferred solution is to set up websites without www, and always with a trailing slash.
If you’re not sure whether these redirects are configured correctly on your website, Seobility’s free Redirect Checker will help you find out:
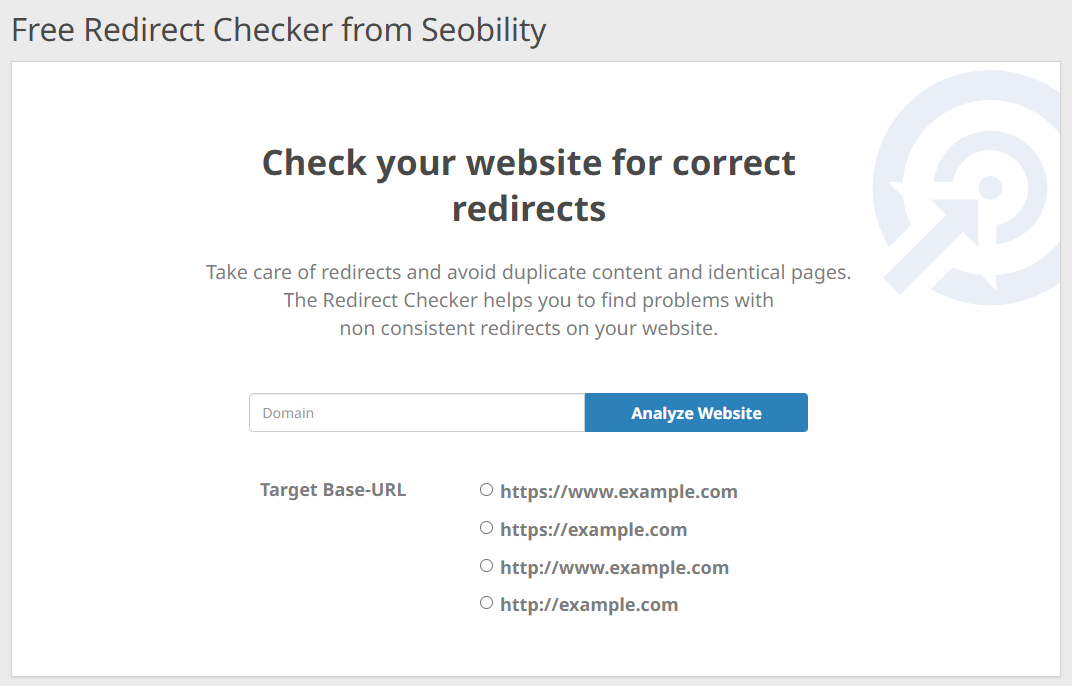
Just enter your domain and select your preferred URL format and the tool will automatically check if your https/www redirects work as intended.
At the bottom of the results page, you’ll also find a Redirect Generator that will generate the necessary code to copy and paste into your .htaccess file on Apache or NGINX server config to set up these rules correctly, if that’s not already the case.
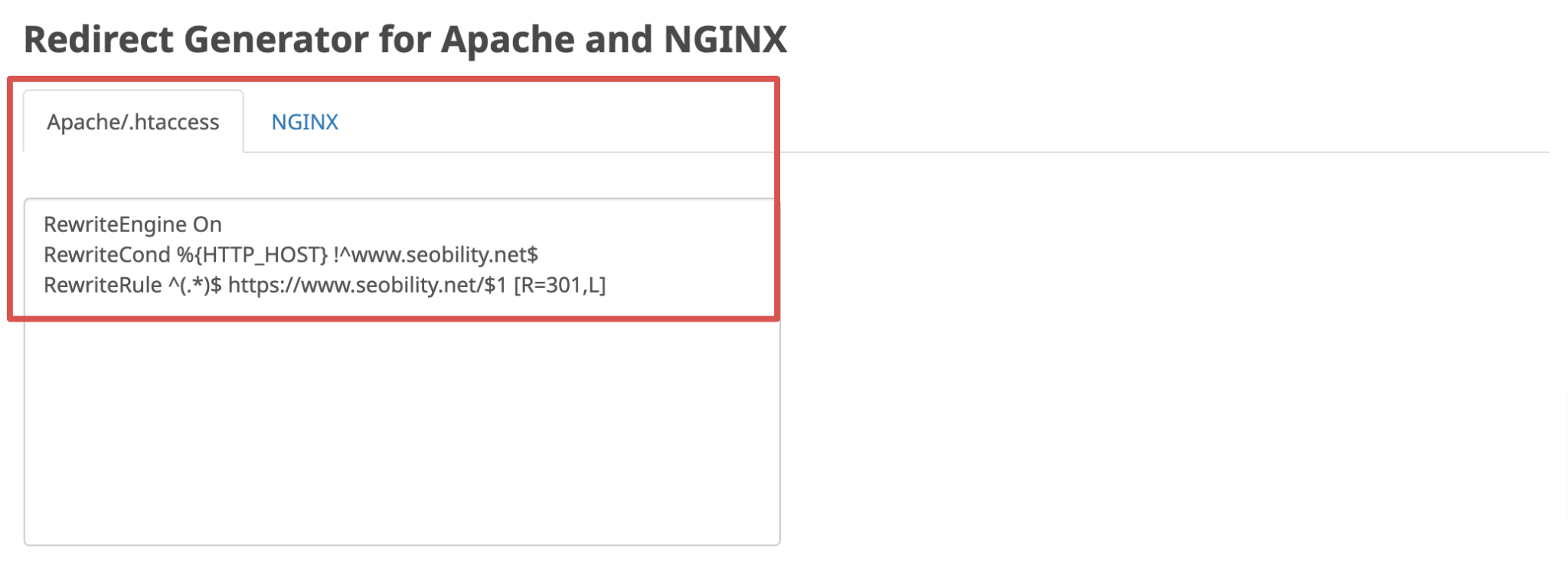
In addition to setting up the redirects correctly, you should also make sure that the canonical tags are correct.
They often get overlooked, but if you’re using HTTPS and your canonical tag points to HTTP, Google will index HTTP. The issue is that if HTTP then also redirects to HTTPS, it creates an infinite loop, which doesn’t please Google.
On WordPress, the most popular SEO plugins, like Yoast and Rankmath, will likely change the canonical tags automatically when you switch from HTTP to HTTPS. However, you might have to change the main site address URL in the settings.
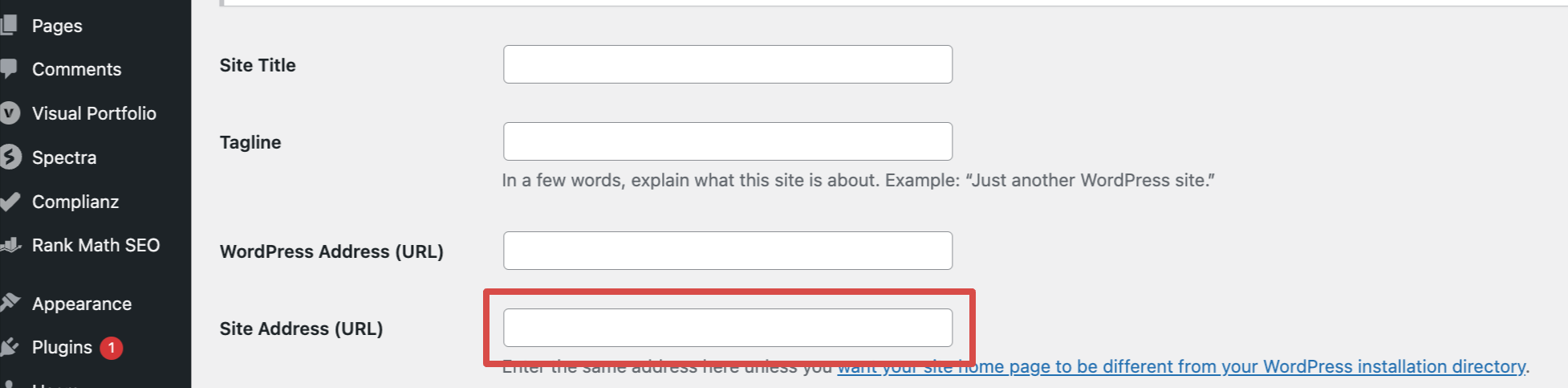
If you’re not using an SEO plugin, you’ll need to add/edit the canonical tags manually. They should be added within the <head> section of your HTML and point to the HTTPS version of each page.
For example, the page https://example.com/page-1 should have a self-referential canonical tag pointing to https://example.com/page-1 (i.e. the same URL) to make it clear that this is the page you want Google to index.
Multi-Language Management Issues
In a similar vein to content management, a lot of content sites have issues with duplicate content due to partially or wholly un-translated content.
If you use WordPress, you might be familiar with multi-language plugins like Polylang and WPML. These plugins make it easy to clone existing content in your primary language with the intention of translating it into a new language.
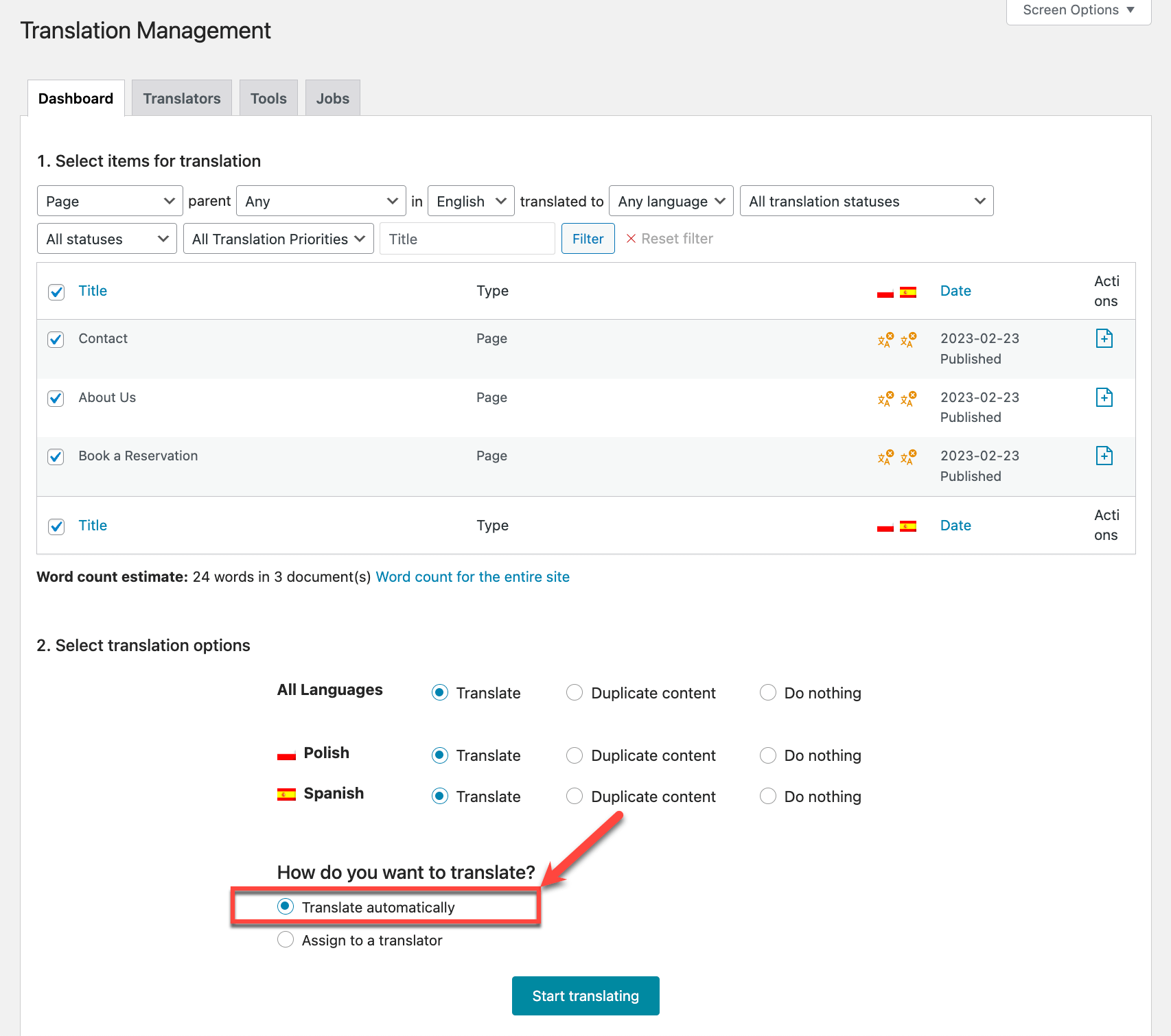
In many cases though, content is often cloned and forgotten about, as team members don’t often browse the site in a different language. Blocks of content, or even entire pages and blog posts end up being available in English, despite the page’s hreflang denoting a different language.
If you are using one of these plugins, take the time to review each page and post of content, in each language to ensure that 100% of it is translated. Seobility’s Duplicate Content Analysis can save you a lot of time here, especially if you have thousands of URLs worth of content (more on this later).
After discovering untranslated content, either task your content team with translating it, translate it automatically, or consider deleting that piece of untranslated content in the specific language.
If you decide to delete the content entirely, make sure you:
- Remove or change any internal links pointing to the content (as explained in the section “Literally Duplicated Content”)
- Adjust hreflang links from your multi-language plugin dashboard
- Update your sitemap if necessary to reflect Google the changes you’ve made
Product Pages on eCommerce Websites
Ecommerce SEO managers are becoming increasingly detail-oriented, but for the longest time auto-generated product pages based on imported product listings was the name of the game.
In product ranges with a large number of variations, such as automotive parts or clothing, duplicate content would be common.
Here’s an example from the wild:
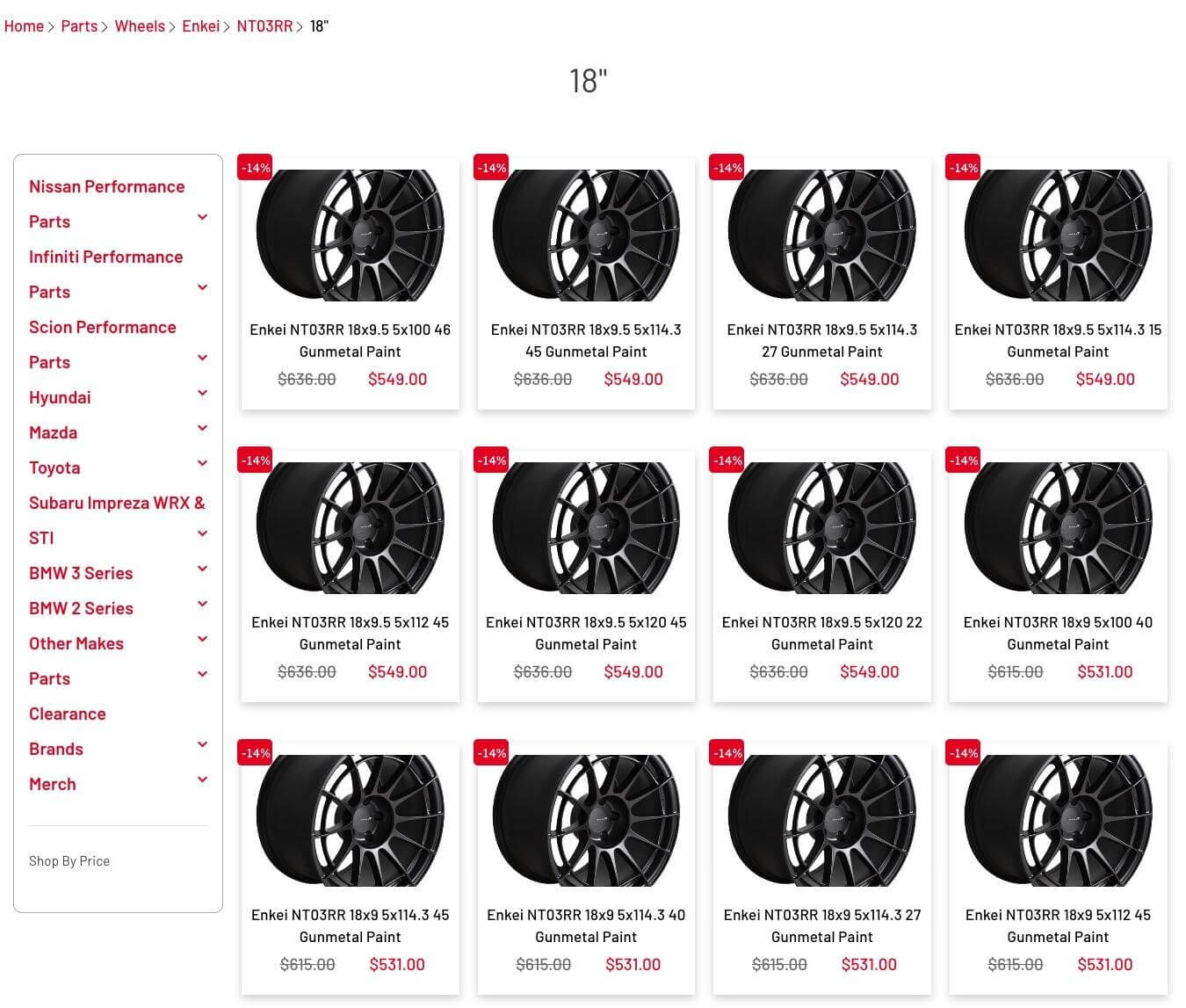
Every single product variation has a different URL. Though the title is partially unique, the image and product descriptions are identical.
While one could argue that individual products could rank for very specific long-tail keywords (and that is true), let’s be real – if you’re not taking the care to provide unique product info on each page, it’s not going to perform.
This site owner is far better off with a single product URL that offers 12 variations via a drop-down menu.
For more information on how to optimize your eCommerce site’s product pages, including how to handle similar products as well as product variations, check out Seobility’s in-depth guide on SEO for eCommerce product pages.
Pagination
Pagination is a technique used to divide large groups of content into multiple pages. Picture the blog home page on a website that has 2,500 blog posts or an ecommerce website with 200 products in each of its 12 categories.
Instead of loading all the content in a single, lengthy page that is slow to load and has too many links, pagination allows users to navigate through smaller, more manageable chunks of content.
By clicking through lists of posts or products via links (typically numbered) at the bottom of each page, user experience, site speed, and SEO are improved. Google itself provides a good example of this on its results pages:

Sometimes though, paginated category pages may have a lengthy introduction block on the page or supporting content below the product list, and this is repeated every time it is paginated, creating duplicate content.
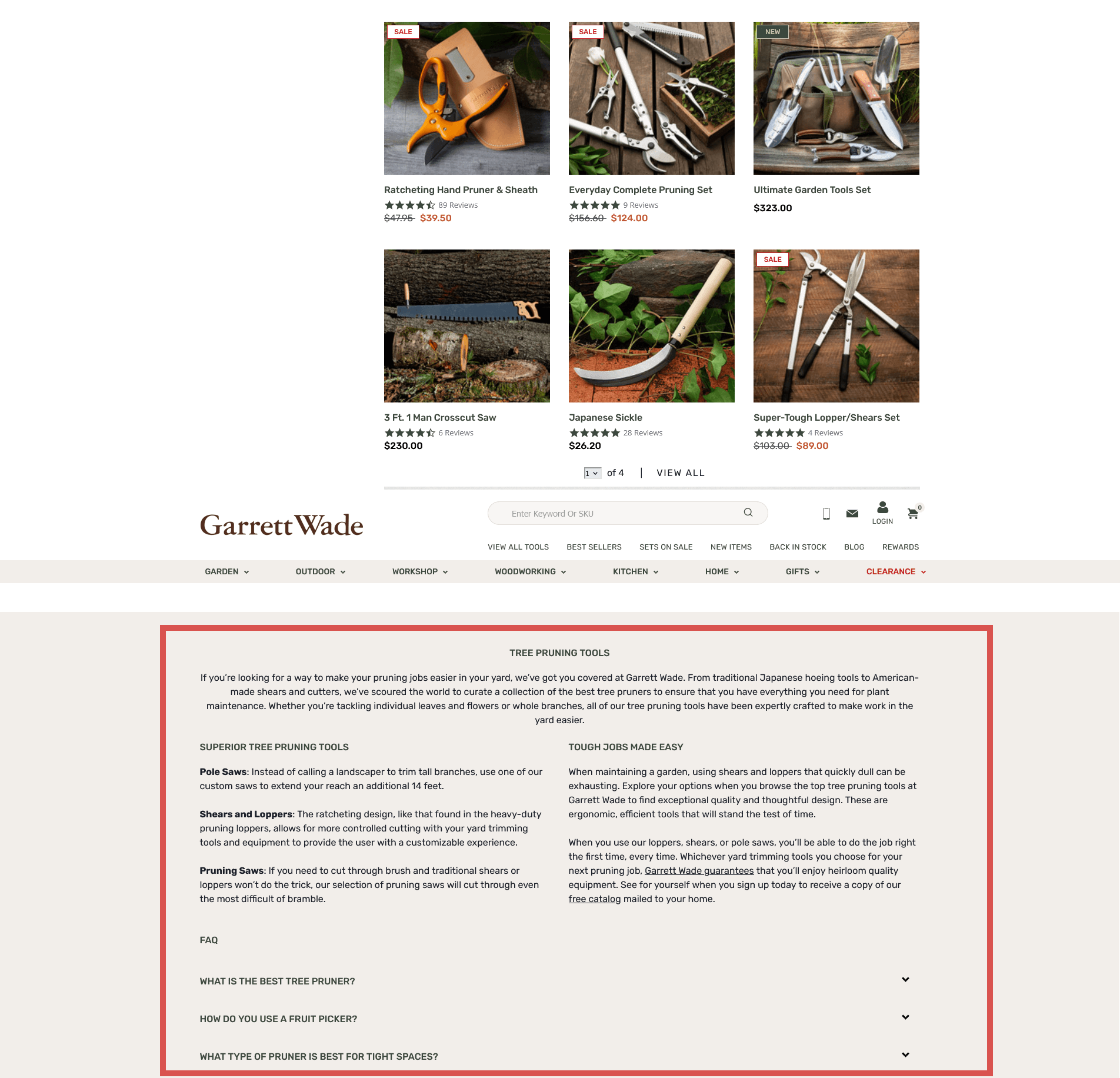
To avoid this, ask yourself if you really need pagination in the first place. If the content can easily be displayed on one page without affecting load times and user experience, then you should go for it, as it will remove a lot of complexity from your site.
However, if you have hundreds or thousands of items in a category, this won’t be an option.
In this case, you should only use the content on page 1 of your pagination and remove it from all subsequent pages. This will not only avoid duplicate content, but will also give Google an important hint to display page 1 of your pagination in its search results, rather than picking another page. To further reduce the likelihood of Google displaying page 4 or 5 of your pagination instead of page 1, you can “de-optimize” the paginated pages, for example by choosing a title such as “Results page 4 of category …”.
If this is not possible due to technical limitations of your CMS or similar reasons, an alternative solution is to set all pages starting from page 2 of your pagination to noindex. However, this solution has a major drawback: Google will eventually stop following all links on noindexed pages. This means that if you have important links on your paginated pages (e.g. links to product pages), you need to make sure that Google can access the linked pages in other ways before implementing this solution, e.g. by providing an optimized XML Sitemap that includes these links.
One method of dealing with paginated content that is sometimes suggested by SEOs, but which Google doesn’t recommend, is to set the canonical tag on pages 2, 3, etc. to the first page of the pagination. The goal of this method is to get the first page indexed by Google and to consolidate all the positive ranking signals on that first page while avoiding issues like duplicate content. However, this is not what canonical tags are intended for. If you use them in this way, this would signal to Google that you have only one category page, rather than a paginated series, and as a result it may not discover the pages listed on page 2, 3, and so on.
If you want to dig deeper into this topic, this guide on SEJ provides a great overview of SEO best practices as well as common myths about pagination.
Tags, Categories and Author Archives on WordPress Websites
One of my favorite optimization opportunities on WordPress sites is to turn close attention to tags, categories and author archives.
It’s one of many actions we review when running through our “SEO launchpad” process at Dialed Labs. None of these are inherently bad. It’s only that they’re regularly misused or produce very low-value pages.
Thin Content in Archives
While this isn’t directly related to duplicate content, it’s something that needs to be mentioned when talking about archive pages on WordPress websites.
Both categories and tags are great ways to organize and categorize blog posts. But many site owners and content creators are unaware that WordPress automatically creates an archive page for each new category and tag they create.
Categories are more intuitive, so they seem to be used correctly on most sites. Tags, on the other hand, seem to be seen as some sort of SEO powerup, where people try to use as many as possible on their posts.
As a result, numerous sites end up with an excessive number of tags, leading to a large number of pages with thin content that offer next to no value.
This practice may stem from the outdated notion that “more pages equal better visibility.” I disagree. A small, powerful website that is packed with high-value pages is my preference any day!
If this problem sounds familiar to you, think about which tags you really need for your site and keep only those. If you have tags that only contain 1-2 articles, readers who want to explore more of your site’s content won’t find much value in those tags.
Tags that don’t add value to visitors can be deleted entirely, but make sure you redirect the URLs to a similar page if they have external links pointing to them.
If you don’t want to delete the pages, you can also consider setting them to noindex. The most popular WordPress SEO plugins, such as Yoast SEO and Rankmath, make it easy to noindex these pages from their plugin settings.
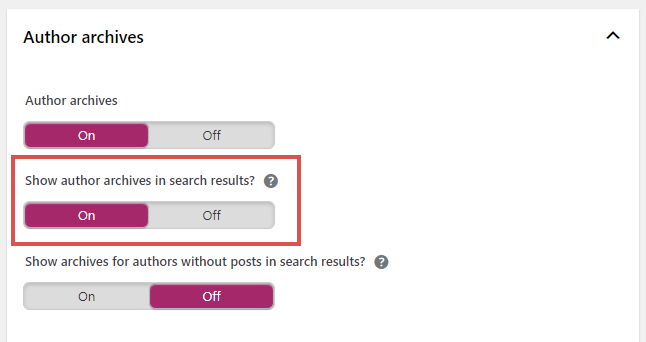
An exception to the noindex rule is when the archive pages are earning organic traffic on their own. For example, your author might be a famous author whose name gets searched naturally. In cases like this, you want to keep the page indexed to continue gaining traffic from Google.
Duplicate Content in Archives
As if thin content wasn’t enough, archive pages can also lead to duplicate content issues if not handled properly.
In site themes that don’t limit archive pages to using only an excerpt of content, blog content can be displayed in its entirety on the home page, in an author archive, category archive and multiple tag archives before we even consider the actual post URL.
An exception to the noindex rule is when the archive pages are earning organic traffic on their own. For example, your author might be a famous author whose name gets searched naturally. In cases like this, you want to keep the page indexed to continue gaining traffic from Google.

The above image shows when an author page is showing too much of the article content (no excerpt limit), leading to duplicate content issues.
Any content displayed on category/author/tag archive pages should only use a small excerpt to avoid duplication. You can do this by using the built-in ”More” block” in WordPress, which will automatically make the excerpt only 10-25 words. For the previous image, this is how the difference would look like:

Another cause of duplicates in archive pages are redundant tags and categories. For example, if you run a digital marketing blog and you have a category called ‘content marketing’, but you also create a tag for ‘content marketing tips’, then both pages are likely to contain the same articles, resulting in duplicate content.
To avoid this, make sure you use unique tags and categories that don’t repeat each other and keep this categorization system as clean as possible. Your categories should be more general and indicate the broad topic of your posts, while tags are usually more specific and help people find similar content after reading one of your posts.
If your website already suffers from duplicate content issues due to redundant categories and tags, it’s time for a clean up. As described in the section “Thin Content in Archives”, think about which of these pages you really need and delete / noindex everything that doesn’t provide value.
How to Discover Duplicate Content
One of the fastest ways to identify duplicate content is through software. An auditing tool like Seobility, which crawls every page on your site, is much faster than trawling for duplicate content manually.
When you kick off a Website Audit in Seobility, the tool will automatically check your website for all types of technical and on-page SEO issues, including various degrees of duplicate content.
If you’re already a user, you can find this through the Onpage > Content > Duplicate content section.
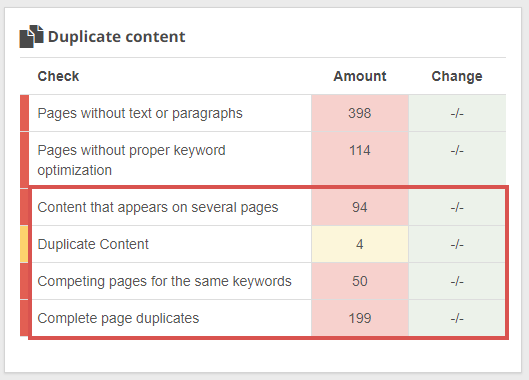
Within Seobility, the types of duplicate content that are checked are defined as:
- Complete page duplicates: identical pages, down to the HTML
- Duplicate Content: pages with identical text content (but not complete HTML duplicates)
- Content that appears on several pages: text blocks that are used on multiple pages
- Competing pages for the same keywords: keyword cannibalization
While keyword cannibalization isn’t strictly a duplicate content issue, it is closely related and absolutely worth reviewing through a content audit.
Monitor and Audit Your Content Performance
Content duplication can seriously hurt your SEO efforts, impeding crawl efficiency and tanking your rankings.
The good news is that simple proactive measures can help you identify and resolve duplicate content issues, safeguarding your website’s position in the SERPs.
Sign up for a free 14-day trial of Seobility and start a website audit today to be sure that you will discover any trouble with duplicate content on your site before Google does!




Really interesting explanations, thank you. I am working right now on duplicate content on my site and this guide is helping me a lot.
That’s great to hear, Matthew! Thanks for your feedback!
Hi Jase and the Seobility Team,
Thank you for this highly detailed and actionable guide. The breakdown of duplicate content causes, especially regarding archive pages and pagination, is absolutely spot on.
As a web developer and SEO strategist, I was auditing some pagination structures and noticed a rather amusing technical irony right here on your blog. In the “Pagination” section of this article, you correctly highlighted that Google does not recommend setting the canonical tag on paginated pages (like page 2, 3) back to the first page.
However, if you inspect your own blog’s pagination (e.g., [https://www.seobility.net/en/blog/page/2/](https://www.seobility.net/en/blog/page/2/)), the canonical tag is currently pointing back to the root /en/blog/. Additionally, the meta title and description on the paginated pages are missing dynamic page variables (like “Page 2”), making them identical to the first page.
It looks like a standard CMS theme default that slipped through the cracks, but I thought I would drop a friendly heads-up so your dev team can implement the self-referencing canonicals you advocate for!
Keep up the fantastic content!
Best regards,
Saad Ahmed
Founder of Generator Fixer.
Hi Saad,
Thank you for your kind words and for sharing this detailed heads-up with us!
You’re right, this was indeed a technical issue that had slipped through. The canonical issue on our paginated blog pages has already been fixed, so the pages now use self-referencing canonicals as recommended.
We also appreciate your note about the meta titles and descriptions on paginated pages. We’ll take a closer look at this as well.
Thanks again for pointing this out so constructively, and for reading our content so closely! 💙