


Duplicate Content ist eines der häufigsten technischen SEO-Probleme, das eine Reihe von negativen Effekten nach sich ziehen kann, darunter eine reduzierte Sichtbarkeit der betroffenen Seiten in Suchmaschinen, verwässerter Link Juice sowie eine frustrierende Nutzererfahrung.
Trotz des Namens ist der Content-Manager Deines Unternehmens aber normalerweise nicht die richtige Person, um dieses Problem zu lösen. Typischerweise handelt es sich bei Duplicate Content nämlich um ein technisches Problem, das einen technischen Lösungsansatz erfordert.
In diesem Blogartikel zeigen wir Dir häufige Ursachen für die Entstehung von Duplicate Content und – wichtiger noch – wir erklären Dir, wie Du diese beheben kannst!
- Was ist Duplicate Content?
- Wie wirkt sich Duplicate Content auf SEO aus?
- Häufige Ursachen für Duplicate Content
- Schlechtes Content-Management
- Falsche Serverkonfiguration
- Multi-Language-Management
- Produktseiten auf E-Commerce-Websites
- Pagination
- Tags, Kategorien und Autorenarchive auf WordPress-Websites
- So findest Du Duplicate Content auf Deiner Website
- Fazit
Was ist Duplicate Content?
Bevor wir uns tiefer in dieses Thema stürzen, sollten wir zunächst klären, was wir unter „Duplicate Content“, also doppelten Inhalten, verstehen. Einfach ausgedrückt, bezieht sich der Begriff auf das Auftreten ein und desselben Inhalts oder sehr ähnlicher Inhalte unter mehreren URLs.
Obwohl der Begriff sich auch auf identische Inhalte auf unterschiedlichen Domains beziehen kann, konzentriert sich dieser Artikel auf doppelte Inhalte, die auf derselben Website auftreten. Dieses Phänomen wird auch als „interner Duplicate Content“ bezeichnet.
Ich spreche hierbei von ganzen Seiten oder umfangreichen Content-Blöcken, die mit anderen Inhalten auf derselben Website entweder vollständig übereinstimmen oder ihnen sehr ähnlich sind.
Wie wirkt sich Duplicate Content auf SEO aus?
Google ist laut eigener Aussage sehr darauf bedacht, „Seiten mit verschiedener Information zu indexieren und anzuzeigen“:
„Unsere User wollen gewöhnlich einen vielfältigen Querschnitt an einzigartigem Content für ihre Suchanfragen erhalten. Sie sind verständlicherweise verärgert, wenn sie im Wesentlichen den gleichen Content innerhalb der Suchergebnisse sehen.“
Während man bei den Aussagen von Google sonst oft zwischen den Zeilen lesen muss, ist die Botschaft in Bezug auf die Bedeutung von einzigartigem Content eindeutig.
Wenn die einzelnen Seiten Deiner Website keine einzigartigen Informationen liefern, wirst Du es schwer haben, die obersten Positionen in den Suchergebnisseiten (SERPs) zu erobern.
Websites mit Duplicate Content leiden unter geringerem organischen Traffic und weniger indexierten Seiten. In Fällen von Manipulation riskieren sie sogar eine algorithmische Abstrafung. Dies hat mehrere Gründe:
-
- Bedenke, dass der Googlebot kein Mensch ist. Wenn er zwei oder mehr Seiten mit demselben Inhalt entdeckt, muss der Algorithmus entscheiden, welche Seite ranken soll. Obwohl dies oft gelingt, kann es auch zu Fehlern kommen.

Figure: Duplicate Content – Author: Seobility – License: CC BY-SA 4.0
- Wenn ein und derselbe Inhalt auf mehreren URLs vorhanden ist, verteilen sich üblicherweise auch positive „Signale“ wie Backlinks, Social Shares und Engagement-Statistiken auf diese URLs. Dadurch profitieren all diese URLs jeweils weniger von diesen Signalen, als es eine einzelne URL tun würde.
- Bei Duplicate Content muss der Googlebot mehr Zeit und Ressourcen für das Crawlen Deiner Website aufwenden, obwohl er keinen Nutzen davon hat. Du vergeudest somit Googles Zeit (und das Crawl-Budget Deiner Website).
In der Suchmaschinenoptimierung gibt es bereits genügend Faktoren, die außerhalb unserer Kontrolle liegen – da solltest Du Google nicht auch noch ein verwirrendes Durcheinander an Inhalten präsentieren und es Google überlassen, diese zu sortieren.
Wenn Du zu einem Vorstellungsgespräch für einen Job eingeladen wirst, den Du wirklich haben willst, kommst Du dann unvorbereitet und in schmutziger Kleidung? Jeder, der die Position wirklich will, zeigt sich von seiner besten Seite und recherchiert gründlich im Vorfeld.
Der Wettbewerb in der organischen Suche wird immer härter, also wollen wir das Gleiche tun und Google die beste und klarste Version unserer Website präsentieren, damit die Suchmaschine diese vollständig versteht.
Häufige Ursachen für Duplicate Content
Probleme mit Duplicate Content können aus verschiedenen Gründen auftreten. Verschiedene Arten von Websites wie Blogs, E-Commerce-Webites usw. haben jeweils spezifische Eigenschaften, die zu Duplicate Content führen können.
Im Folgenden gehe ich auf einige der häufigsten Ursachen für Duplicate Content ein, denen ich bei der Durchführung technischer SEO-Audits für verschiedene Kunden-Websites begegne. Anschließend zeige ich Dir, wie Du diese Probleme beheben kannst, wenn Du sie auf Deiner eigenen Website entdeckst!
Schlechtes Content-Management
Es gibt zweifellos viele technische Probleme, die zu Duplicate Content führen, aber es wäre fahrlässig, nicht zuerst einen Blick auf das Content-Management zu werfen.
Wortwörtlich duplizierter Inhalt
Wenn ich mir eine Website zum ersten Mal anschaue, stoße ich oft schnell auf minderwertige Seiten mit identischem Inhalt und URLs wie z.B:
- https://beispiel.com/test-seite/
- https://beispiel.com/test-seite-1/
- https://beispiel.com/test-seite-2/
Häufig werden Inhalte absichtlich dupliziert, um neue Seiten mit ähnlichem Layout leichter erstellen zu können.
Das ist an sich kein Problem. Ein Problem entsteht erst, wenn man vergisst, hinterher aufzuräumen.
Quelle: https://ofm.od.nih.gov/
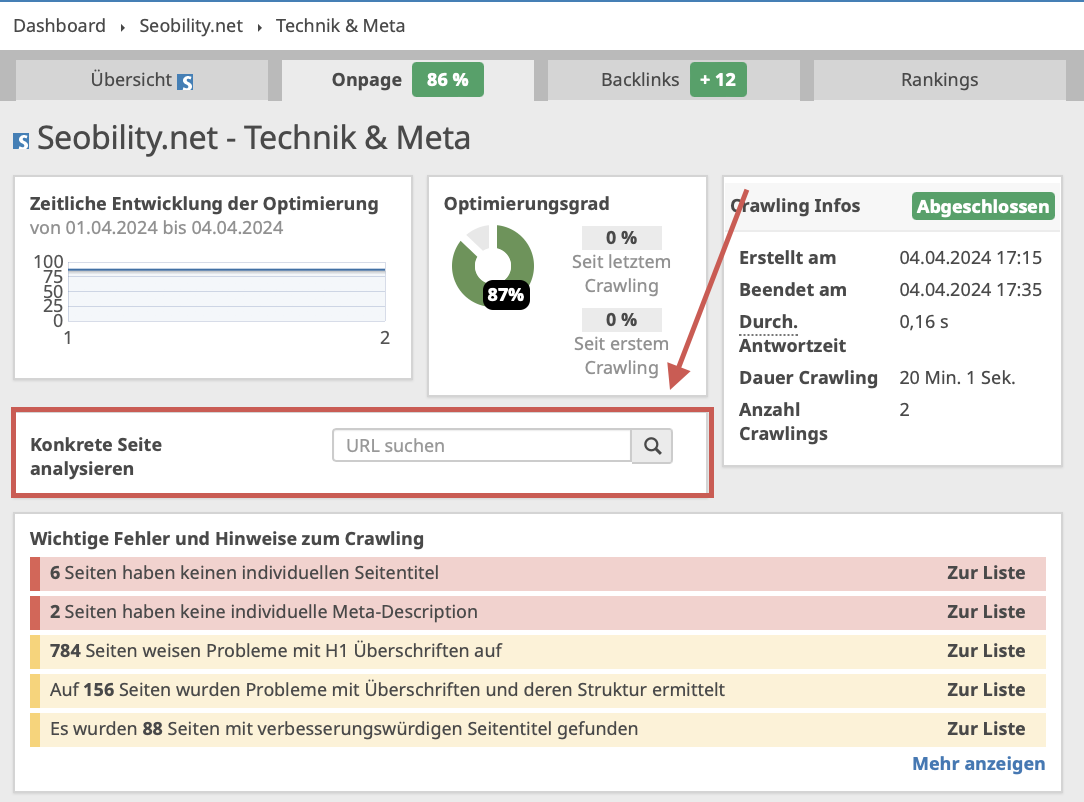
Die gute Nachricht ist, dass dieses Problem leicht behoben werden kann, indem Du die Seiten einfach löschst und einen 404– oder 410-Statuscode ausgibst. Bevor Du dies tust, solltest Du jedoch sicherstellen, dass es keine internen Links auf Deiner Website gibt, die auf diese Seiten verweisen, um Broken Links in Zukunft zu vermeiden. Wenn Du Seobility verwendest, kannst Du dies leicht überprüfen, indem Du im Suchfeld „Konkrete Seite analysieren“ nach der URL suchst, die Du löschen möchtest:
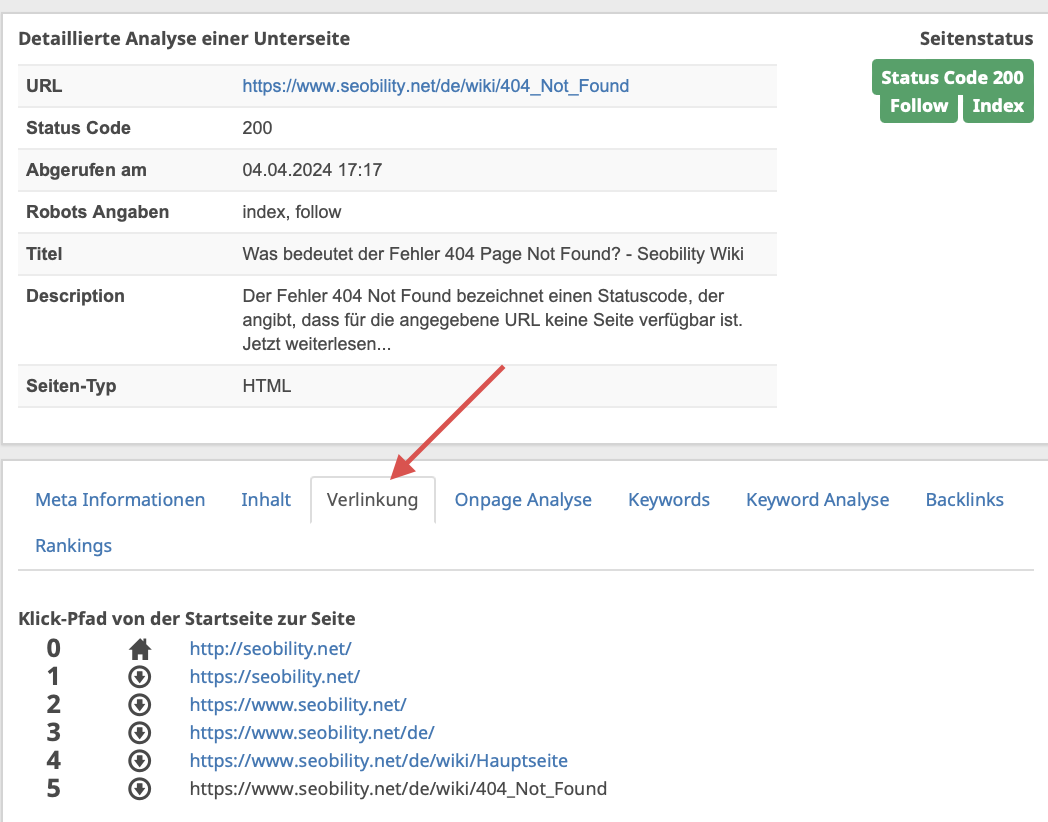
Navigiere dann zum Tab „Verlinkung“, um alle auf diese Seite verweisenden Links zu sehen:
Duplizierte Landingpages
Viele meiner Kunden bauen ihren organischen Traffic aus, während sie gleichzeitig Suchmaschinenwerbung und Facebook-Anzeigen schalten. Dabei erstellen sie häufig Landingpages für ihre Anzeigen, indem sie bestehende Seiten einfach duplizieren.
Nicht selten stößt man auf Folgendes:
- https://example.com/service/
- https://example.com/service-lp-facebook/
- https://example.com/service-lp-googleads/
Zwar unterscheiden sich einige der auf diesen Seiten verwendeten Texte vom Original, doch in der Regel sind Title, Meta-Description sowie 90 % des Inhalts identisch.
In diesem Beispiel soll die Seite /service/ bei Google ranken. Daher ist es wichtig, eine klare Botschaft an die Suchmaschine zu senden.
Alle Landingpages, die für andere Traffic-Quellen genutzt werden, sollten mit der Anweisung „noindex“ versehen werden, damit sie nicht im Google-Index erscheinen und mit den für die organische Suche optimierten Seiten konkurrieren.
Die einzige Ausnahme von dieser Regel ist, wenn Du erwartest, dass diese anderen Landingpages Social-Media-Shares oder Backlinks erhalten. In diesem Fall kannst Du die Seiten indexierbar lassen und stattdessen einen Canonical Link zur Hauptseite /service/ hinterlegen.
Diese “kanonische” URL signalisiert Google, dass die Hauptseite /service/ die „ursprüngliche“ Quelle des Inhalts ist, und diese in den Suchergebnissen angezeigt werden soll. Außerdem werden hierdurch die positiven Signale von Backlinks auf die kanonische Seite gebündelt.
In unserem Beispiel müssten wir allen Landingpages folgenden Canonical Tag hinzufügen:
<link rel="canonical" href="https://example.com/service/" />
Wenn Du diese Methode verwendest, denke daran, dass eine Seite nicht als „noindex“ gekennzeichnet werden sollte, wenn sie auf eine andere kanonische URL verweist. So stellst Du sicher, dass Du Google nicht mit widersprüchlichen Signalen verwirrst.
Dies wurde auch von Googles John Mueller bestätigt:
„[…] man sollte ’noindex‘ und ‚rel=canonical‘ nicht mischen … sie stellen für uns sehr widersprüchliche Informationen dar. Im Allgemeinen bevorzugen wir ‚rel=canonical‘ gegenüber ’noindex‘, aber wann auch immer Du Dich auf die Interpretation durch ein Computerprogramm verlässt, verliert Deine Eingabe an Gewicht.“
Falsche Serverkonfiguration
Google gab 2014 offiziell bekannt, dass HTTPS ein Rankingfaktor ist. 2018 begann Google Chrome damit, Webseiten, die über HTTP geladen werden, als „nicht sicher“ zu markieren.

Alle Websites sollten gesichert sein. Detaillierte Informationen dazu findest Du in diesem Leitfaden zum Wechsel von HTTP zu HTTPS.
Bei vielen über HTTPS ausgelieferten Websites kommt es jedoch aufgrund fehlender Weiterleitungen häufig zu problematischen Doppelungen, sodass der gleiche Inhalt unter zwei oder mehr URLs abrufbar ist.
Einfach ausgedrückt: Wenn Deine Website sowohl über HTTP als auch über HTTPS erreichbar ist und es keine Weiterleitung von einer Version auf die andere gibt, entsteht Duplicate Content. Und das gilt nicht nur für eine Seite, sondern für alle Unterseiten der gesamten Website!
Deine Website sollte also nicht gleichzeitig unter https://example.com und http://example.com erreichbar sein.
Ebenso wenig sollte sie sowohl auf einer Subdomain als auch auf der Hauptdomain verfügbar sein, wie zum Beispiel unter https://www.example.com und https://example.com.
Aber selbst wenn Du die Verwaltung Deiner Domains im Griff hast, gibt es andere Faktoren, die zu problematischen Doppelungen führen können, wie zum Beispiel ein einfacher Trailing Slash am Ende Deiner URLs.
https://example.com/service sollte nicht unter https://example.com/service/ erreichbar sein und umgekehrt.
In all diesen Fällen ist es wichtig, Redirects einzurichten, die Besucher automatisch zu Deiner bevorzugten URL-Variante weiterleiten. Dies sollte immer die HTTPS-Version sein, damit eine sichere Verbindung für alle Websitebesucher gewährleistet werden kann. Von dort aus musst Du entscheiden, wie Du Deine Subdomains (www oder nicht www in den meisten Fällen) und Permalinks (mit oder ohne abschließenden Trailing Slash) einrichten möchtest.
Meine bevorzugte Lösung ist es, Websites ohne www einzurichten und immer mit einem abschließenden Trailing Slash
Wenn Du Dir nicht sicher bist, ob diese Weiterleitungen auf Deiner Website richtig konfiguriert sind, kannst Du das mit dem kostenlosen Redirect Check von Seobility herausfinden:
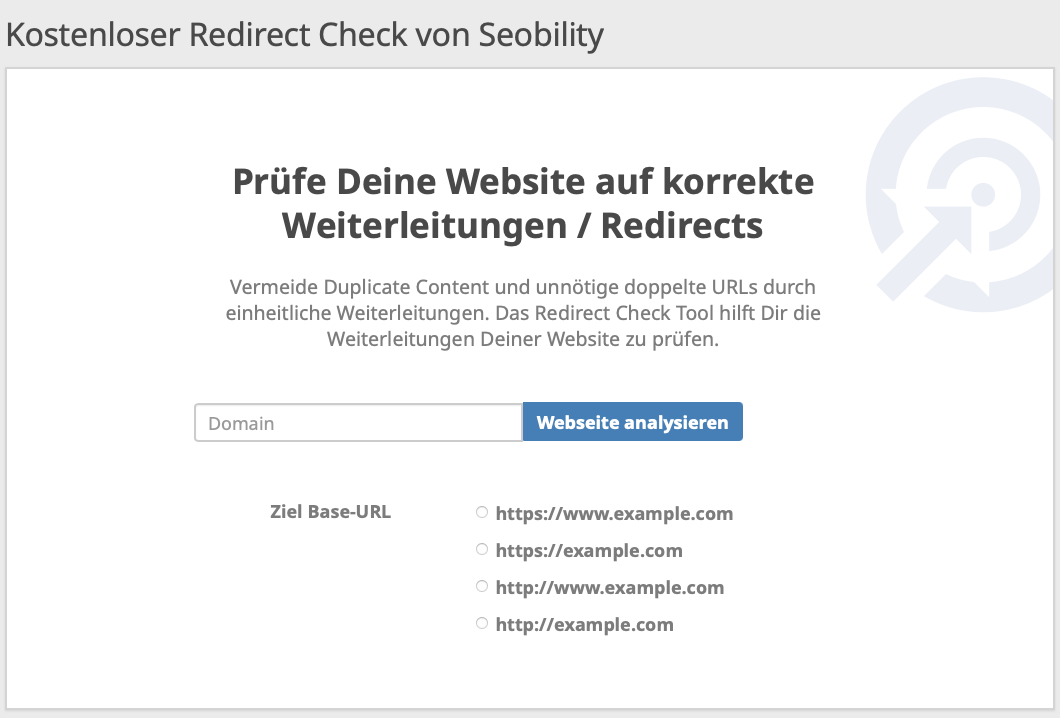
Gib einfach Deine Domain ein und wähle Dein bevorzugtes URL-Format aus. Das Tool überprüft automatisch, ob Deine https/www-Redirects wie gewünscht funktionieren.
Am Ende der Ergebnisseite findest Du außerdem einen Redirect Generator, der den erforderlichen Code generiert. Diesen kannst Du einfach kopieren und in Deine .htaccess-Datei auf dem Apache-Server oder in Deine NGINX-Server-Konfiguration einfügen, falls die Regeln noch nicht korrekt eingerichtet sind.
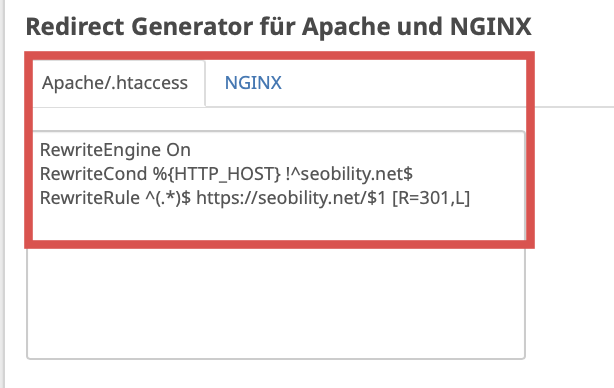
Neben der korrekten Einrichtung von Weiterleitungen solltest Du auch darauf achten, dass die Canonical Tags korrekt gesetzt sind.
Sie werden oft übersehen, aber wenn Du HTTPS verwendest und Dein Canonical Tag auf HTTP verweist, wird Google die HTTP-Version indexieren. Wenn diese wiederum per Redirect auf HTTPS weiterleitet, entsteht eine Endlosschleife für den Googlebot.
Gängige SEO-Plugins wie Yoast und Rankmath passen die Canonical Tags in WordPress oft automatisch an, wenn Du von HTTP auf HTTPS umstellst. Es kann jedoch sein, dass Du die Haupt-URL der Website in den Einstellungen anpassen musst.
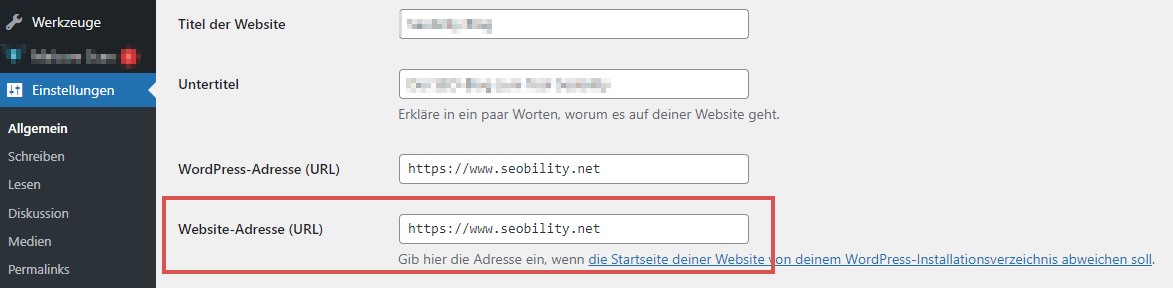
Wenn Du kein SEO-Plug-in verwendest, musst Du die Canonical Tags manuell hinzufügen bzw. bearbeiten. Sie sollten innerhalb des <head>-Bereichs Deines HTML-Codes hinzugefügt werden und auf die HTTPS-Version jeder Seite verweisen.
Dabei sollte zum Beispiel auch die Seite https://example.com/seite-1 einen Canonical Tag auf “sich selbst” haben, also auf https://example.com/seite-1 verweisen, um klarzustellen, dass dies die Seite ist, die Google indexieren soll.
Multi-Language-Management
Wie auch beim Content-Management stoßen viele Websitebetreiber auf Probleme mit Duplicate Content durch teilweise oder komplett fehlende Übersetzungen von Inhalten.
Wenn Du WordPress nutzt, bist Du vielleicht schon auf Muli-Language-Plug-ins wie Polylang oder WPML gestoßen. Diese Tools ermöglichen es, bestehende Inhalte in der Primärsprache zu klonen, um sie anschließend in eine andere Sprache zu übersetzen.
Es kommt jedoch häufig vor, dass kopierte Inhalte in Vergessenheit geraten, da die Teammitglieder die Website selten in einer anderen Sprache besuchen. So bleiben Textblöcke oder sogar ganze Seiten und Blogbeiträge in der Ausgangssprache, obwohl das hreflang-Attribut eine andere Sprache angibt.
Wenn Du eines dieser Plugins verwendest, solltest Du Dir die Zeit nehmen, jede Seite und jeden Beitrag in jeder Sprache zu überprüfen, um sicherzustellen, dass alle Inhalte zu 100 % übersetzt wurden. Die Duplicate-Content-Analyse von Seobility kann Dir hier viel Zeit ersparen, insbesondere wenn Du tausende URLs an Inhalten hast (mehr dazu später).
Nachdem Du nicht übersetzte Inhalte entdeckt hast, kannst Du Dein Content-Team mit der Übersetzung beauftragen, die Übersetzung automatisch durchführen oder erwägen, den spezifischen Inhalt in der betreffenden Sprache zu löschen.
Wenn Du Dich dafür entscheidest, den Inhalt komplett zu entfernen, vergewissere Dich, dass Du:
- jegliche internen Links, die auf den Inhalt verweisen, entfernst oder austauschst (wie im Abschnitt „Wortwörtlich duplizierter Inhalt“ erklärt),
- hreflang-Links über das Dashboard Deines Multi-Language-Plug-ins anpasst und
- Deine Sitemap aktualisierst, um Google über die vorgenommenen Änderungen zu informieren.
Produktseiten auf E-Commerce-Websites
SEO-Manager im E-Commerce-Bereich werden immer detailorientierter, doch früher wurden Produktseiten oft automatisch anhand importierter Produktlisten erstellt.
Besonders in Produktkategorien mit einer großen Anzahl an Variationen, wie beispielsweise bei Autoteilen oder Bekleidung, war Duplicate Content an der Tagesordnung.
Hier ein Beispiel aus der Praxis:
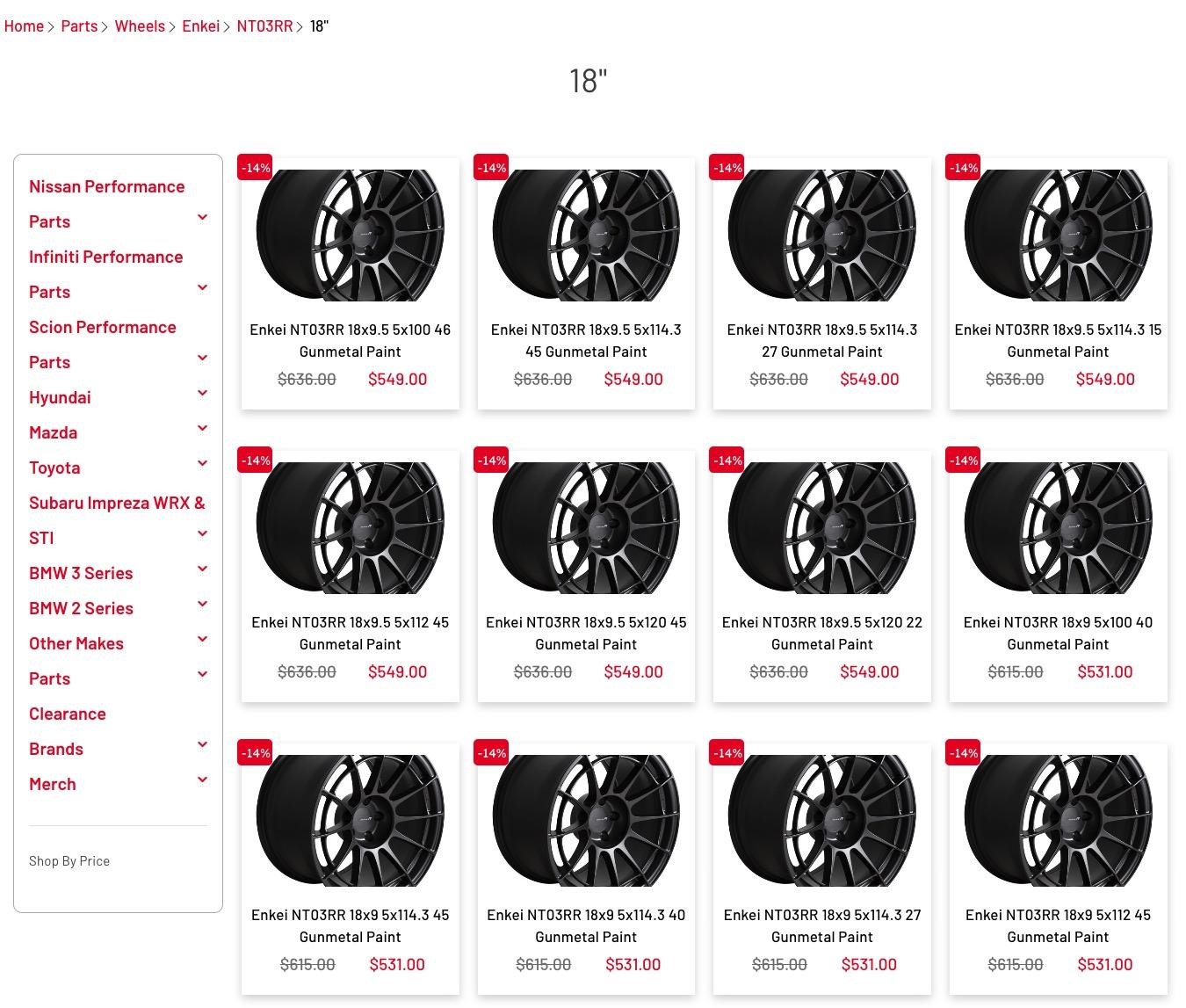
Jede einzelne Produktvariante hat eine eigene URL. Auch wenn der Titel teilweise einzigartig ist, sind das Bild und die Produktbeschreibungen identisch.
Man könnte zwar argumentieren, dass einzelne Produkte durchaus für sehr spezifische Longtail-Keywords ranken können (und das stimmt auch), aber seien wir ehrlich: Wenn nicht für jede Seite einzigartige Produktinformationen bereitgestellt werden, wird sie nicht performen.
Der Betreiber des Webshops ist deutlich besser beraten, eine einzige Produkt-URL bereitzustellen, die 12 Variationen über ein Dropdown-Menü anbietet.
Weitere Informationen dazu, wie Du die Produktseiten Deiner E-Commerce-Website optimieren und mit ähnlichen Produkten sowie Produktvarianten umgehen kannst, findest Du in unserem ausführlichen Leitfaden zu SEO für E-Commerce-Produktseiten.
Pagination
Pagination ist eine Technik, die verwendet wird, um große Mengen an Inhalten auf mehrere Seiten aufzuteilen. Stell Dir die Startseite eines Blogs mit 2.500 Blogartikeln oder eine E-Commerce-Website mit 200 Produkten in jeder ihrer 12 Kategorien vor.
Anstatt alle Inhalte auf einer einzigen, langen Seite zu platzieren, die langsam lädt und zu viele Links enthält, ermöglicht es die Pagination den Nutzern, durch kleinere, handlichere Teile des Contents zu navigieren.
Das Durchklicken von Artikel- oder Produktlisten über (in der Regel nummerierte) Links am unteren Rand jeder Seite verbessert die Benutzererfahrung, die Seitengeschwindigkeit und die SEO-Performance.
Online-Shops wie Amazon liefern ein gutes Beispiel dafür auf ihren Ergebnisseiten:

Manchmal haben paginierte Kategorieseiten allerdings einen langen Einführungstext auf der Seite oder unterstützenden Inhalt unterhalb der Produktliste, der bei jeder Paginierung wiederholt wird, was wiederum zu Duplicate Content führt.
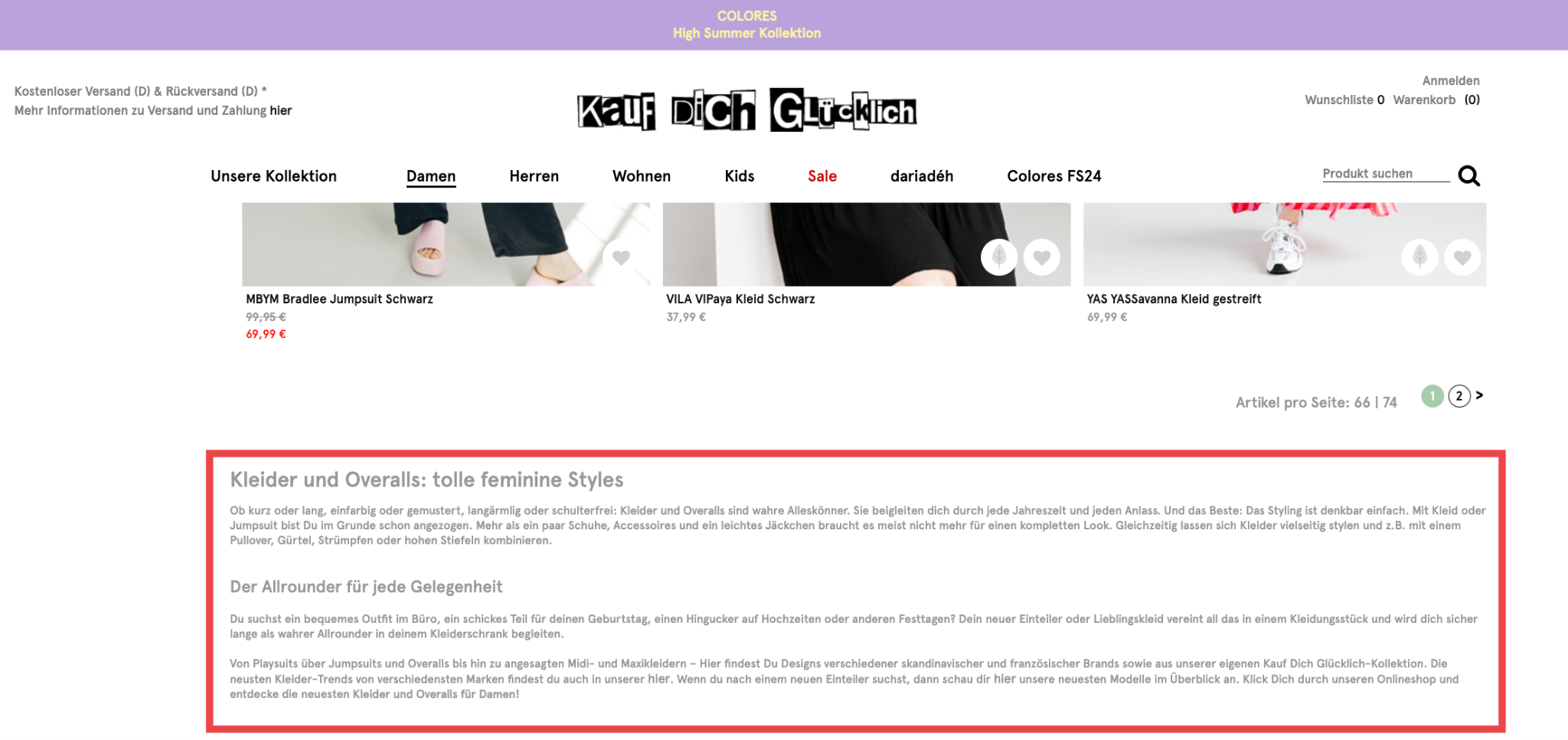
Um dies zu vermeiden, frag Dich vorweg, ob Du überhaupt eine Pagination brauchst. Wenn der Inhalt problemlos auf einer Seite angezeigt werden kann, ohne Ladezeiten und User Experience zu beeinträchtigen, dann solltest Du Dich besser gegen die Pagination entscheiden, weil Deine Website dadurch weniger komplex wird.
Wenn Du jedoch Hunderte oder Tausende von Artikeln in einer Kategorie hast, wirst Du keine Wahl haben. In diesem Fall solltest Du den Textinhalt ausschließlich auf Seite 1 Deiner Pagination verwenden und ihn von den darauffolgenden Seiten entfernen. So vermeidest Du nicht nur Duplicate Content, sondern gibst Google auch einen wichtigen Hinweis, die Seite 1 Deiner Pagination anstelle einer anderen Seite in den Suchergebnissen anzuzeigen. Um die Wahrscheinlichkeit weiter zu reduzieren, dass Google z.B. Seite 4 oder 5 Deiner Pagination anstelle von Seite 1 anzeigt, kannst Du die paginierten Seiten „de-optimieren“, indem Du z.B. einen Titel wie „Ergebnisseite 4 der Kategorie …“ wählst.
Wenn dies aufgrund von technischen Einschränkungen Deines CMS oder aus anderen Gründen nicht umsetzbar ist, besteht eine alternative Lösung darin, alle Seiten ab Seite 2 der Pagination auf noindex zu setzen. Diese Lösung hat aber einen großen Nachteil: Google folgt nach einer gewissen Zeit den Links auf noindex Seiten nicht mehr. Das bedeutet: wenn Du wichtige Links auf den paginierten Seiten hast (z.B. Links zu Produktseiten), musst Du unbedingt sicherstellen, dass Google diese Seiten auf andere Weise „finden“ kann, bevor Du diese Lösung implementierst. Am einfachsten ist das möglich, indem Du eine optimierte XML-Sitemap bereitstellst, die Links zu den wichtigen Seiten enthält.
Eine Methode im Umgang mit paginierten Inhalten, die manchmal von SEOs vorgeschlagen, aber von Google nicht empfohlen wird, ist das Setzen von Canonical Tags auf den Seiten 2, 3 usw., um auf die erste Seite der Paginierung zu verweisen. Das Ziel dieser Methode ist es, die erste Seite von Google indexieren zu lassen und alle positiven Ranking-Signale auf dieser ersten Seite zu bündeln, während Probleme wie Duplicate Content vermieden werden.
Dies ist jedoch nicht der Zweck von Cannonical Tags. Wenn Du sie auf diese Weise verwendest, signalisierst Du Google, dass Du nur eine Kategorieseite und keine paginierte Serie hast, was zur Folge haben kann, dass Google die auf Seite 2, 3 usw. aufgelisteten Seiten möglicherweise nicht entdeckt.
Wer sich näher mit dem Thema beschäftigen möchte, findet in diesem englischsprachigen Leitfaden auf SEJ einen guten Überblick über SEO Best Practices und gängige Mythen rund um das Thema Paginierung.
Tags, Kategorien und Autorenarchive auf WordPress-Websites
Eine meiner bevorzugten Methoden zur Optimierung von WordPress-Websites ist es, die Tags, Kategorien und Autorenarchive genauer unter die Lupe zu nehmen.
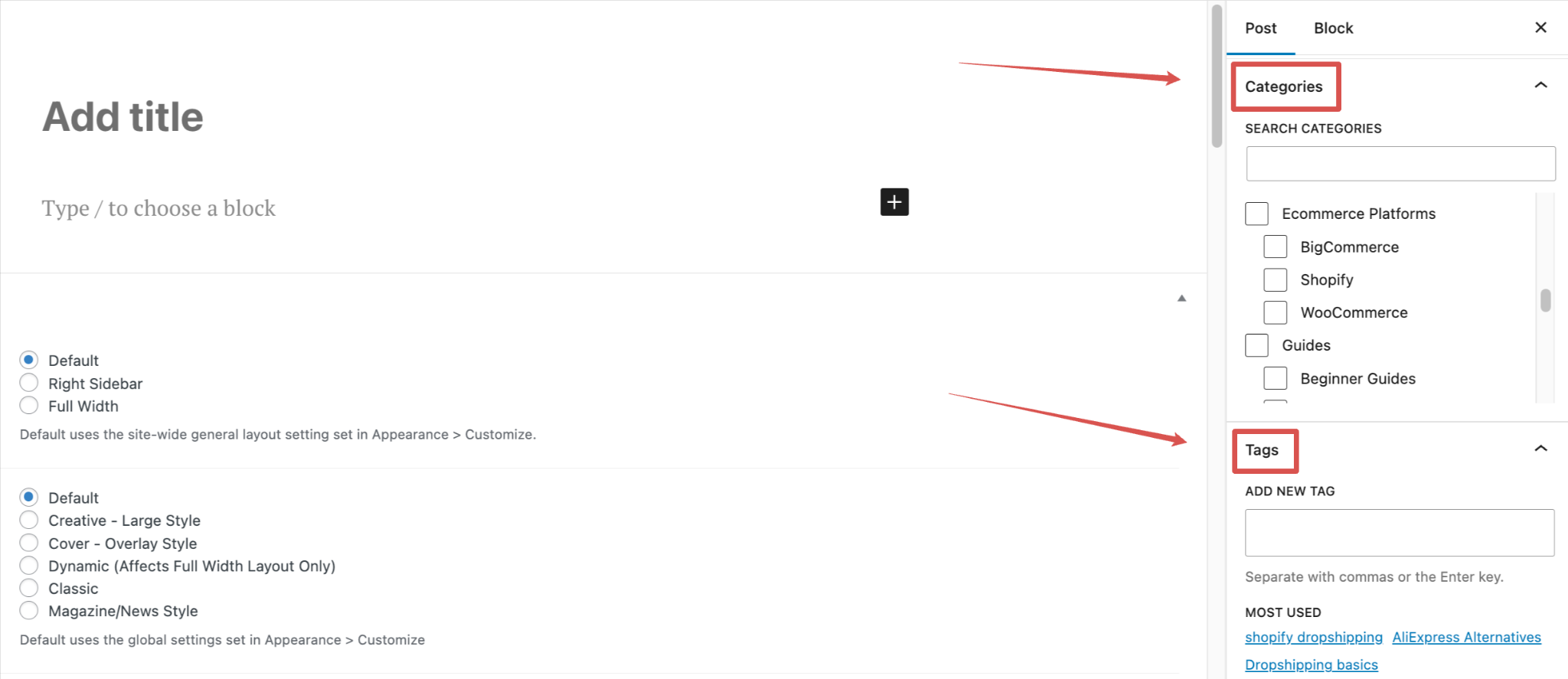
An sich ist keines dieser Elemente schlecht. Das Problem ist, dass sie oft falsch eingesetzt werden oder zu minderwertigen Seiten führen.
Thin Content in Archiven
Auch wenn dieses Problem nicht direkt mit Duplicate Content zusammenhängt, sollte es dennoch erwähnt werden, wenn es um Archivseiten auf WordPress-Websites geht.
Kategorien und Tags sind tolle Möglichkeiten, um Blogbeiträge zu organisieren und zu kategorisieren. Vielen Website-Betreibern und Content-Erstellern ist jedoch nicht bewusst, dass WordPress für jede neu angelegte Kategorie und jedes neu angelegte Tag automatisch eine Archivseite anlegt.
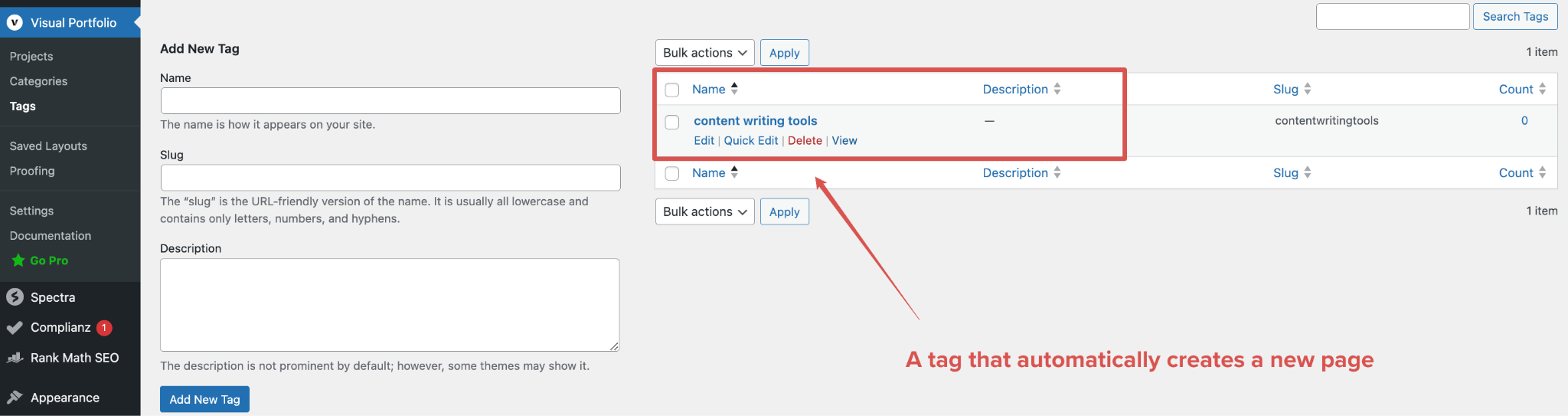
„Ein Tag, der automatisch eine neue Seite erzeugt”
Kategorien sind intuitiver und scheinen daher auf den meisten Websites korrekt verwendet zu werden. Tags hingegen werden oft als eine Art SEO-Booster angesehen, und es wir oft versucht, so viele wie möglich davon zu verwenden.
Das Ergebnis ist, dass viele Websites zu viele Tags haben, was zu einer großen Anzahl von Seiten mit Thin Content führt, die wenig Mehrwert bieten.
Diese Vorgehensweise mag auf der veralteten Vorstellung beruhen, dass „mehr Seiten gleich bessere Sichtbarkeit“ bedeuten. Ich bin da anderer Meinung. Eine kleine, leistungsstarke Website mit hochwertigen Seiten ist mir allemal lieber!
Wenn Dir dieses Problem bekannt vorkommt, überlege Dir, welche Tags Du für Deine Website wirklich brauchst und behalte nur diese. Wenn Du Tags hast, die nur 1 oder 2 Artikel enthalten, haben Leser, die mehr Inhalte auf Deiner Website durchstöbern wollen, kaum einen Mehrwert durch diese Tags.
Tags, die den Besuchern keinen Mehrwert bieten, können komplett gelöscht werden. Stelle jedoch sicher, dass Du die URLs auf eine ähnliche Seite weiterleitest, falls externe Links darauf verweisen.
Wenn Du die Seiten nicht löschen möchtest, kannst Du sie auch auf noindex setzen. Die beliebtesten WordPress-SEO-Plugins, wie Yoast SEO und Rankmath, machen es leicht, diese Seiten über die Plugin-Einstellungen aus den Suchergebnissen auszuschließen.
Eine Ausnahme von der noindex-Regel besteht, wenn die Archivseiten selbst organischen Traffic generieren. Das könnte zum Beispiel der Fall sein, wenn Dein Autor ein bekannter Autor ist, dessen Name natürlich gesucht wird. In solchen Fällen solltest Du die Seite indexiert lassen, um weiterhin Traffic von Google zu erhalten.
Duplicate Content in Archiven
Als ob Thin Content an sich nicht schon problematisch genug wäre, können Archivseiten ebenfalls zu Problemen mit Duplicate Content führen, wenn sie nicht angemessen verwaltet werden.
Manchmal kommt es vor, dass Archivseiten nicht nur einen kurzen Auszug der gelisteten Blogartikel darstellen, sondern sehr lange Vorschautexte oder sogar den kompletten Artikelinhalt anzeigen. Das führt dann im schlimmsten Fall dazu, dass der Inhalt eines Artikels auf der Blog-Startseite, in einem Autorenarchiv, einem Kategoriearchiv und mehreren Tag-Archiven angezeigt wird, noch bevor die eigentliche URL des Beitrags aufgerufen wird.

Auf dem obigen Bild ist eine Autorenseite zu sehen, die zu viel vom Artikelinhalt anzeigt (keine Begrenzung des Auszugs). Das führt zu Problemen mit Duplicate Content.
Alle Inhalte, die auf Kategorie-/Autor-/Tag-Archivseiten angezeigt werden, sollten nur einen kleinen Auszug verwenden, um Duplikate zu vermeiden. Dies kannst Du erreichen, indem Du den integrierten „Mehr“-Block in WordPress verwendest, der automatisch dafür sorgt, dass der Auszug nur 10 bis 25 Wörter umfasst. Für das vorherige Bild würde der Unterschied folgendermaßen aussehen:

Ein weitere häufige Ursache für Duplikate auf Archivseiten sind redundante Tags und Kategorien. Wenn Du beispielsweise einen Blog über Digitales Marketing betreibst und eine Kategorie namens „Content Marketing“ hast, aber auch ein Tag für „’Content Marketing Tipps“ erstellst, dann enthalten beide Seiten wahrscheinlich die gleichen Artikel, was zu Duplicate Content führt.
Um dies zu vermeiden, solltest Du sicherstellen, dass Du eindeutige Tags und Kategorien verwendest, die sich nicht wiederholen, und das Kategorisierungssystem so übersichtlich wie möglich halten. Deine Kategorien sollten etwas weiter gefasst sein und das allgemeine Thema Deiner Beiträge widerspiegeln. Tags sollten spezifischer sein und den Nutzern helfen, nach dem Lesen Deines Beitrags ähnliche Inhalte zu bestimmten Schlagworten zu finden.
Wenn Deine Website bereits Probleme mit Duplicate Content durch überflüssige Kategorien und Tags hat, ist es Zeit für eine Aufräumaktion. Wie im Abschnitt „Thin Content in Archives“ beschrieben, überlege Dir, welche dieser Seiten Du wirklich benötigst und lösche oder setze alles, was keinen Mehrwert bietet, auf noindex.
So findest Du Duplicate Content auf Deiner Website
Eine der einfachsten und schnellsten Möglichkeiten, Duplicate Content aufzuspüren, ist der Einsatz von Software. Ein Website Audit Tool wie Seobility, das jede Seite Deiner Website automatisch durchkämmt, ist wesentlich schneller als die manuelle Suche nach Duplicate Content.
Wenn Du ein Website-Audit in Seobility startest, überprüft das Tool automatisch Deine Website auf verschiedenste technische und Onpage-SEO-Probleme, einschließlich Duplicate Content.
Wenn Du bereits Nutzer bist, kannst Du die Duplicate Content Analyse im Bereich Onpage > Inhalt > Duplicate Content finden.
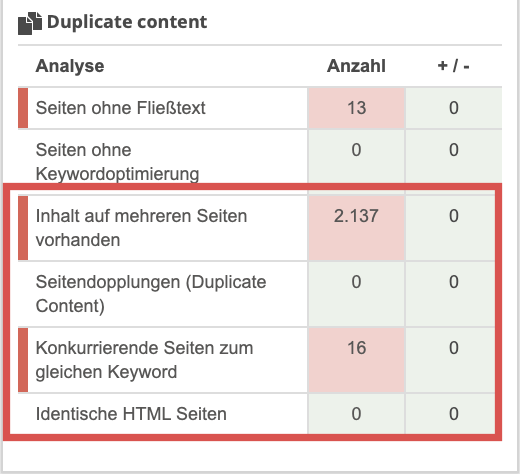
Bei Seobility werden die folgenden Arten von Duplicate Content überprüft:
- Komplette Seitenduplikate: Vollständig identische HTML-Seiten
- Duplicate Content: Seiten mit identischem Textinhalt (aber keine kompletten HTML-Duplikate)
- Inhalt auf mehreren Seiten vorhanden: Textblöcke, die auf mehreren Seiten verwendet werden
- Konkurrierende Seiten für dieselben Keywords: Keyword-Kannibalisierung
Obwohl Keyword Kannibalisierung streng genommen kein Duplicate-Content-Problem ist, steht sie doch in engem Zusammenhang damit und sollte unbedingt im Rahmen eines Website- bzw. Content-Audits geprüft werden.
Fazit
Duplicate Content kann sich negativ auf Deine SEO-Bemühungen auswirken, indem er Google das Crawling Deiner Website erschwert und zu schlechteren Rankings der betroffenen Seiten führt.
Die gute Nachricht ist, dass Du mit einfachen proaktiven Maßnahmen Probleme mit Duplicate Content frühzeitig erkennen und beheben kannst, um die Position Deiner Website in den SERPs zu sichern.
Registriere Dich für eine kostenlose 14-tägige Testversion von Seobility und starte noch heute ein Website-Audit, um sicherzustellen, dass Du Probleme mit Duplicate Content auf Deiner Website entdeckst, bevor Google es tut!




