
Definition
Punycode is an encoding standard developed for use with internationalized domain names. It allows for the encoding and representation of Unicode characters for use in hostname resolution that only supports ASCII (American Standard Code for Information Interchange) characters. This means that, for example, a domain name can be comprised of Chinese characters. Punycode then encodes those characters and makes them referable in an ASCII format.
As Unicode represents more than just international character sets, Punycode can also be used to allow for hostnames that use emojis. This is not a widely supported standard, so there is only a limited subset of top-level domains that support emojis in domain names.
Background
The technology that powers the internet stretches as far back as the 1960s and was developed primarily by Americans. It is because of this that ASCII historically became the default encoding standard for many computers and servers. ASCII was limited to 128 characters, which were comprised mainly of the Latin alphabet, numbers, and punctuation marks.
ASCII offered no means of encoding characters from other writing systems, like Kanji, Hangul, or Cyrillic. This provided a barrier to entry for many who cannot read the Latin alphabet and meant that companies in those markets could not use truly localized domain names.
Unicode was an encoding system developed to be expandable and cater to as many different characters as possible. ASCII is very rarely used today, but a lot of old software and hardware still runs on ASCII encoding. In order to bridge the gap between modern systems using Unicode and older systems using ASCII, Punycode was created.
Examples
Punycode is useful for processing internationalized domain names. As an example, Korea uses its own character system called Hangul. Hangul characters cannot be properly encoded using ASCII, so Punycode takes strings encoded with Unicode and converts them into something readable (and resolvable) using ASCII.
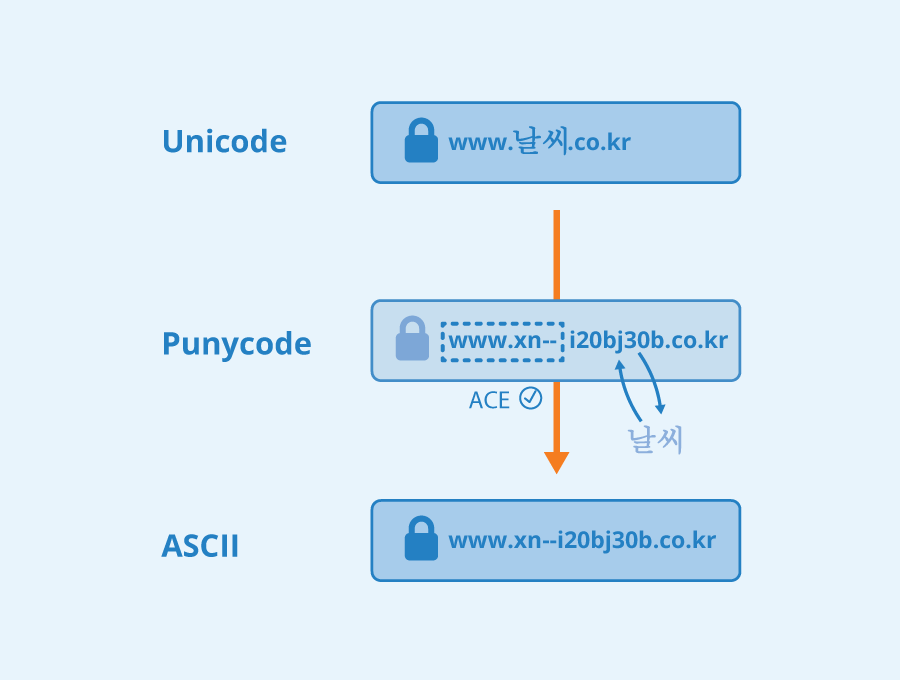
Before Punycode, companies and services operating in markets like Korea would have to adapt their brands to fit the ASCII restrictions. For example, ‘날씨 ‘ means ‘weather’ in Korean. A website would have to change its domain name to something like ‘www.weather.co.kr’. With Punycode, they can use a domain name like ‘www.날씨.co.kr’ instead, which allows brands to use their proper identities and services to be truly localized for markets that do not natively use the Latin alphabet. Punycode support also works for top-level domains, so it is possible to have internet hostnames composed entirely of non-ASCII characters that are resolvable on ASCII systems with Punycode.
For the string ‘날씨’, Punycode would convert this to ‘xn--i20bj30b’. This is a unique string that allows ASCII systems to read and interpret a string using characters outside of the ASCII standard. ASCII systems will interpret the URL ‘www.날씨.co.kr’ as ‘www.xn--i20bj30b.co.kr’. It is worth noting that most browsers will display the Punycode result in their address bar to prevent phishing attacks.
Punycode phishing attacks can happen when someone registers a domain name using a Punycode encoded string. Certain Punycode domain strings can be bought that, when interpreted, look very similar to domain names of big brands, but actually swap out a single character with a visually similar character from another character set, making it virtually undetectable.
How does Punycode work?
Punycode works as an instance of the boot string algorithm. The boot string algorithm allows for the representation of an arbitrary set of characters for use within a limited set of characters.
This is done by interpreting any string passed to it and analyzing it for non-ASCII characters. Punycode then goes through a number of steps to create a string that is usable on ASCII systems.
Firstly, all characters are normalized by converting them into lowercase where applicable. Then, the characters are searched for ASCII compatibility. Any characters found that exist within the ASCII character set are ignored; however, non-standard ASCII characters are removed from within the text and a hyphen is placed at the end of the string.
If non-standard characters are found, the prefix ‘xn--‘ is added to the string. This signifies that the string contains ACE (ASCII Compatible Encoding) and that the hyphen appended should be interpreted using Punycode instead of as part of the string itself.
Punycode then analyses the non-ASCII characters and appends a string of characters to the hyphen that uses ASCII characters to dictate which characters should be represented and where they should be placed within the string. It does this while ensuring that the end result does not exceed the 63-character limit.
Related links
Similar articles
