

Die User Experience einer Website ist ein wichtiger Faktor für ihr Suchmaschinen-Ranking. JavaScript (JS) kann hierbei eine sehr wertvolle Technologie sein, denn damit lassen sich für User dynamische und interaktive Inhalte schaffen.
Aber leider ist das auch nicht ganz unproblematisch: Suchmaschinen und ihre Crawler sind nämlich nicht ganz so angetan von JavaScript. Google und einige andere Suchmaschinen können zwar JavaScript-Inhalte ausführen und indexieren, aber viele Crawler tun sich dennoch schwer damit. Besonders problematisch ist es für KI-Crawler, von denen die meisten gar nicht in der Lage sind, JavaScript richtig zu verarbeiten.
Was das für Dich bedeutet? Wenn Deine Website Inhalte dynamisch über JavaScript lädt, kann das die Sichtbarkeit Deiner Inhalte erheblich beeinträchtigen. Das gilt sowohl für die traditionellen organischen Suchergebnisse als auch für die immer beliebter werdende KI-gestützte Suche.
In diesem Leitfaden sehen wir uns die Herausforderungen bei der Verwendung von JavaScript auf Deiner Website an und teilen SEO-Best-Practices, mit denen Du diese Probleme angehen kannst. Außerdem zeigen wir Dir, wie Seobility bei der Analyse und Optimierung Deiner JavaScript-Website helfen kann.
Wenn Du Dir nicht ganz sicher bist, was JavaScript eigentlich ist und wie das Ganze funktioniert, empfehlen wir Dir vor dem Lesen dieses Leitfadens unseren Wiki-Artikel zu JavaScript.
Was macht JavaScript-SEO so besonders?
Wenn JavaScript zum dynamischen Laden und Anzeigen von Inhalten verwendet wird, spricht man von Client-Side Rendering (CSR). Das bedeutet, dass das Client-Gerät (also der Browser des Users) JavaScript-Inhalte verarbeiten muss, um die Seite auf dem Gerät des Users zu rendern (d. h. verarbeiten und anzeigen). Dies steht im Gegensatz zum Server-Side Rendering, bei dem der Server der Website vorab gerendertes HTML für den Browser generiert. Hier ist also bereits alles für den User vorbereitet und Tools, die kein JavaScript verwenden, wissen schneller, was sie anzeigen sollen.
JavaScript eignet sich hervorragend zum Erstellen dynamischer Inhalte, zum Beispiel für Quizzes:
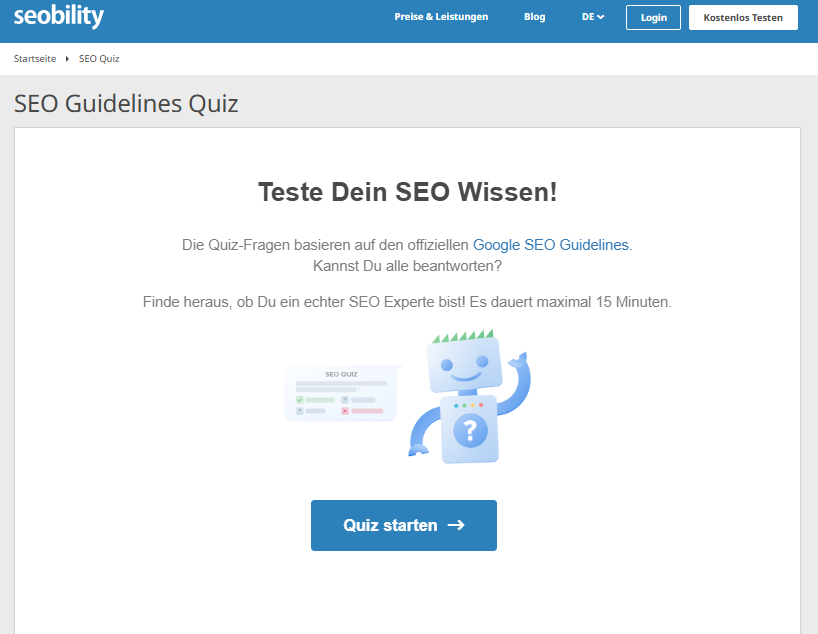 Dynamische, über JavaScript hinzugefügte Inhalte können eine Website interaktiver und ansprechender machen, doch diese Inhalte sind nicht immer für alle Suchmaschinen und Crawler sichtbar.
Dynamische, über JavaScript hinzugefügte Inhalte können eine Website interaktiver und ansprechender machen, doch diese Inhalte sind nicht immer für alle Suchmaschinen und Crawler sichtbar.
User lieben und teilen solche Inhalte gerne, aber leider müssen wir davon ausgehen, dass viele Suchmaschinen nur statische Inhalte, die ohne JavaScript angezeigt werden, crawlen. In unserem Fall heißt das, Crawler sehen nicht den Inhalt, der nach Klick auf den Button „Quiz starten“ angezeigt wird:
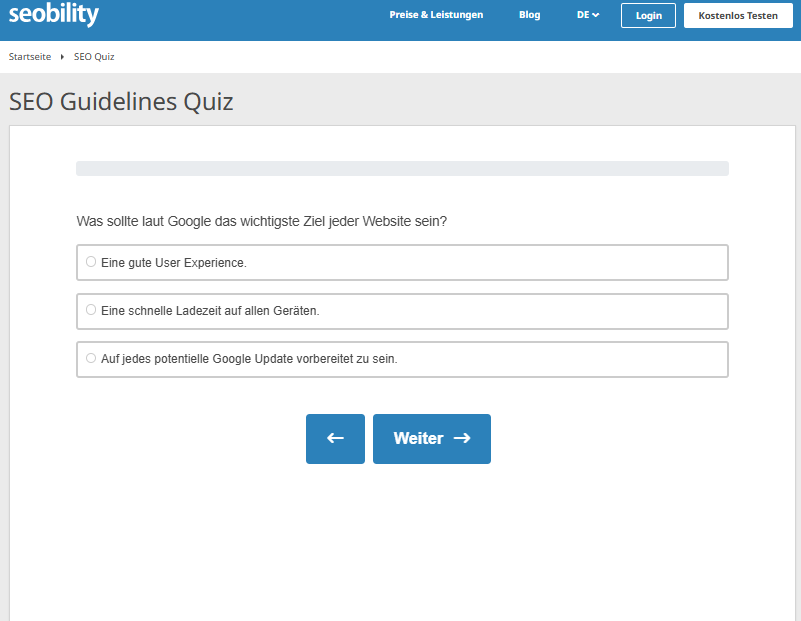
Das mag vielleicht kein Problem sein, wenn es nur um ein kleines Quiz geht. Aber bei wichtigeren Inhalten sieht das schon ganz anders aus.
Wenn Du gut ranken willst, musst Du Deine Inhalte also so gestalten, dass sie für Suchmaschinen-Crawler bereit und lesbar sind, auch wenn Du JavaScript und Client-Side Rendering nutzt. Obwohl einige hohe Tiere bei Google zur Vorsicht mit JavaScript geraten haben, kann Googlebot JS-Inhalte rendern und Bingbot ist ihm dicht auf den Fersen. Andere Suchmaschinen und KI-Crawler haben allerdings oft Schwierigkeiten, über JavaScript gelieferte Inhalte zu verarbeiten.
Zusammenfassend sei gesagt: Um die Herausforderung des Client-Side Renderings zu lösen, musst Du Dein JavaScript in der Regel optimieren und sicherstellen, dass wichtige Inhalte immer vom Server vorgerendert werden, ohne auf JavaScript angewiesen zu sein. So stellst Du sicher, dass Google und andere Crawler nichts Wesentliches übersehen. Wir werden an späterer Stelle noch ausführlicher darüber sprechen, wie Du das umsetzen kannst.
| Client-side Rendering (CSR) | Server-side Rendering (SSR) | |
| Wie werden Inhalte angezeigt (Rendering) | Nutzt die Ressourcen des Besucher-Geräts, um Inhalte mit JavaScript zu rendern. | Wird auf dem Server vor dem Anzeigen als vorgerendertes HTML erzeugt. |
| Warum es Usern gefällt | Dynamische, interaktive Websites & personalisierte User Experience. | Seiten werden schneller geladen, einfachere Indexierung, bessere technische SEO. |
| Crawling | Suchmaschinen und wichtige Crawler können dynamisch geladene Inhalte möglicherweise nicht sehen. | Sofort für die Indexierung durch alle Suchmaschinen und wichtigen Crawler bereit. |
Die Herausforderungen bei der JavaScript-Optimierung
Aufgrund der Tatsache, dass JavaScript-SEO überhaupt ein Thema ist (so etwas wie PHP-SEO gibt es schließlich nicht, oder?), kannst Du Dir wahrscheinlich schon denken, dass es hierbei einige Herausforderungen gibt. Wir gehen hier auf einige der größeren ein.
JavaScript-Frameworks
Manche im Web Development gern genutzten JavaScript-Frameworks wie React, Angular oder Vue können neue Inhalte laden, ohne dass dabei die Seite vollständig neu lädt. Sie werden beispielsweise eingesetzt, um die Startseite, die „Über uns“-Seite und Datenschutzrichtlinien eines Unternehmens über dieselbe URL anzuzeigen, ohne dass sich die URL in der Adressleiste jemals ändert.
Dies wird als Routing bezeichnet. Routing ändert den Zustand einer Seite, also das, was auf dem Bildschirm angezeigt wird, ohne dass die gesamte Seite und ihre Adresse geändert wird.
Für Suchmaschinen kann das problematisch sein, da sie in der Regel eine eindeutige URL für jede Seite erwarten. Wenn sich der Inhalt ändert, aber die URL gleich bleibt, ist es möglich, dass Teile der Website nicht indexiert werden.
Crawling und Indexierung
Wenn eine Suchmaschine JavaScript-basierte Inhalte nicht richtig lesen kann, werden diese in den Suchergebnissen nicht angezeigt. Das kann beispielsweise passieren, wenn Informationen wie Produktdetails, Bewertungen oder Preise von externen Diensten geladen werden (zum Beispiel von einem Bewertungs- oder Lagerverwaltungs-Plugin, das Daten von einer anderen Website oder aus Unternehmenssystemen bezieht). Da diese Inhalte erst nach dem Laden der Seite erscheinen, kann es sein, dass Suchmaschinen sie nicht „sehen“ oder verarbeiten. In manchen Fällen wird ihnen der Zugriff sogar komplett verwehrt.
JavaScript kann außerdem, basierend auf User Sessions, viele Versionen derselben Seite mit leicht unterschiedlichen URLs erzeugen. Das passiert oft, wenn Tracking-Codes oder Filter zur URL hinzugefügt werden. Dadurch können Probleme mit Duplicate Content entstehen. Dieses Problem kannst Du allerdings mit Canonical Tags in den Griff bekommen.
KI-Crawler
Eine Studie von Vercel über KI-Crawler hat ergeben, dass viele der aktuell führenden KI-Crawler (ChatGPT, Claude, Meta, Bytespider und Perplexity) nicht in der Lage sind, JavaScript auszuführen. Wir wissen noch nicht, ob sich Gartners Vorhersage bewahrheiten wird und KI-Sprachmodelle (LLMs) traditionelle Suchmaschinen ersetzen werden. Aber wir kennen wahrscheinlich alle jemanden, der ChatGPT oder Claude bereits wie eine Suchmaschine nutzt.
Wenn Du in diesen LLM-basierten Suchergebnissen angezeigt werden möchtest, solltest Du unbedingt dafür sorgen, dass Deine Inhalte dafür zugänglich sind.
Performance und Nachhaltigkeit
Mehrere, große oder schlecht optimierte JavaScript-Dateien können das Rendering blockieren. Das bedeutet, dass die Seite erst dann richtig angezeigt werden kann, wenn das JS und alle zugehörigen Elemente vollständig vom Gerät des Nutzers heruntergeladen und verarbeitet wurden, was den Lade- und Anzeigevorgang verlängern kann.
Ebenso kann es eine eher unschöne Layoutverschiebung, auch als Cumulative Layout Shift (CLS) bekannt, zur Folge haben. Hier wird der Inhalt aufgrund von spät ladenden Inhalten „live umgestaltet“. Ein klassisches Beispiel für diese Umgestaltung, die wir alle schon gesehen haben: Eine eCommerce-Website lädt zunächst, aber wenige Sekunden später erscheint oben ein Banner mit den neuesten Angeboten, wodurch sich die Inhalte darunter verschieben. Dies kann sich sowohl erheblich auf die Performance als auch auf die User Experience auswirken. Und wir wissen, dass beides wichtige Rankingfaktoren sind …
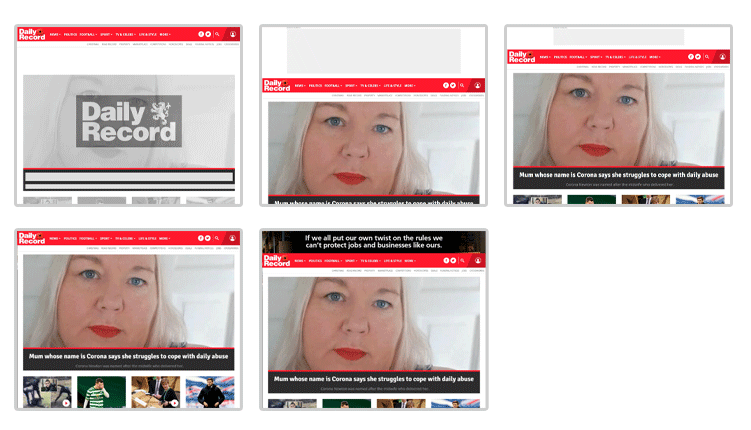
Ein Beispiel für Cumulative Layout Shift: Das Layout dieser Seite ändert sich mehrmals während des Ladens.
Gleichzeitig erhöht die Übertragung großer Dateien und Client-Side Rendering deutlich den CO2-Fußabdruck von Websites. Das Bewusstsein für digitales CO2 wächst und mit der bevorstehenden Einführung der W3W Web Sustainability Guidelines ist jetzt ein guter Zeitpunkt, Dir die Auswirkungen Deines JavaScript-Renderings genauer anzuschauen.
Tracking und Analytics
Oftmals sind Tools wie Google Analytics selbst JavaScript-basiert. Das heißt, dass es hier bei JavaScript-lastigen Websites wiederum zu Konflikten kommen kann. Wenn Tracking-Skripte nicht geladen werden oder sich das Laden deutlich verzögert, werden User-Interaktionen möglicherweise nicht richtig erfasst. Das wirkt sich negativ auf die Qualität Deiner Analytics-Daten aus.
Structured Data und andere Optimierungen
Einige SEO- und Internationalisierungs-Tools nutzen JavaScript, um Schema-Markup (Structured Data) oder lokalisierte Inhalte auf einer Website einzufügen. Das betrifft beispielsweise ALT-Attribute, manchmal aber auch Meta-Tags und Seiteninhalte.
Es ist jedoch ziemlich riskant, sich beim dynamischen Einfügen wichtiger Inhalte auf JavaScript zu verlassen. Beispielsweise kannst Du dir so die Chance verbauen, in Rich-Snippet-Suchergebnissen zu erscheinen, wenn Dein Schema-Markup nicht erkannt wird. Oder es kann passieren, dass Suchmaschinen alternative Sprachversionen Deiner Inhalte nicht finden.
JavaScript SEO Best Practices
Du weißt jetzt, dass es (viele) Herausforderungen gibt. Allerdings besteht deshalb noch lange kein Grund zur Panik. Denk dran, dass nicht jedes JavaScript dieselben Probleme mit sich bringt und selbst wenn, gibt es in der Regel gute Wege, diese sowohl für User als auch für die Suchmaschinenoptimierung zu lösen.
Verzichte auf JavaScript, wenn es keinen Mehrwert bietet
JavaScript an sich ist keine schlechte Sache. Oftmals ist es der effektivste Weg, um bestimmte Funktionen für Barrierefreiheit hinzuzufügen, wie zum Beispiel Dark Mode oder reponsive Menüs.
Dennoch lohnt es sich zu überlegen, ob Deine geplanten Inhalte wirklich in JavaScript bereitgestellt werden müssen. Gibt es vielleicht eine andere Möglichkeit? Eine, die wichtige Inhalte nicht vor Crawlern verbirgt? Bevor Du mit Deinen Optimierungen weitermachst, solltest Du sicherstellen, dass sämtliche Inhalte, die permanent angezeigt werden sollen, unabhängig von JavaScript bereitgestellt werden.
Rendere wichtige Inhalte ohne JavaScript
Achte darauf, dass wichtige Inhalte wie Above-the-Fold-Inhalte, Metadaten, Bilder, Links und Schema-Markup für Suchmaschinen auch ohne JavaScript zugänglich sind. Server-side Rendering (SSR), auch bekannt als Pre-Rendering oder Static Site Generation (SSG), bedeutet, dass die Seite vollständig aufgebaut wird, bevor sie an den Browser gesendet wird. Bei JavaScript-lastigen Websites, bei denen vollständige SSR- oder SSG-Ansätze nicht in Frage kommen, kann dynamisches Rendering eine effektive Alternative sein. Hierbei wird Suchmaschinen und anderen Crawlern eine vorgerenderte Version angezeigt, während menschliche Besucher in den Genuss der vollständigen interaktiven Experience mit JavaScript kommen.
Einige Frameworks wie Next.js oder Nuxt.js unterstützen diese duale Einrichtung von Haus aus. Für andere JavaScript-Frameworks gibt es ebenfalls entsprechende Tools.
Ein Tool, das man dafür nutzen kann, ist beispielsweise Prerender. Prerender erstellt automatisch indexierbare Versionen Deiner Seiten. Hier erfährst Du mehr über Pre-Rendering.
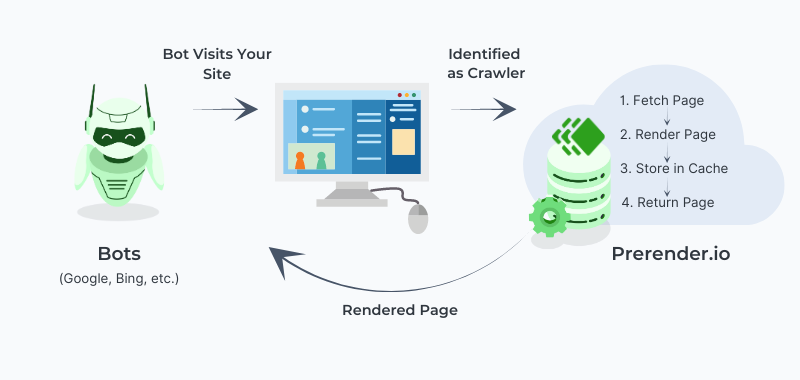
So funktioniert Pre-Rendering (Quelle)
Der Grundgedanke ist, dass Deine wichtigsten Inhalte immer verfügbar und bereit für die Indexierung sind, selbst wenn JavaScript zu spät zum Rendering-Date kommt.
Nutze SEO-freundliches Lazy Loading und Progressive Enhancement
Gestalte Deine Website so, dass grundlegende Inhalte immer geladen werden können, selbst wenn JavaScript nicht funktioniert oder andere Elemente länger zum Laden brauchen. Beim Progressive Enhancement geht es darum, eine funktionale Basis in statischem HTML bereitzustellen, die auch ohne JavaScript lädt und die wichtigsten Anforderungen erfüllt. JavaScript wird dann genutzt, um interaktive Funktionen hinzuzufügen.
Ein Blogbeitrag kann beispielsweise so gestaltet werden, dass Text und Bilder zuerst angezeigt werden, während Zusatzfunktionen wie ein interaktiver Kommentarbereich erst später, wenn JavaScript verfügbar ist, erscheinen. So stellst Du sicher, dass Deine wichtigsten Inhalte zugänglich und indexierbar bleiben, selbst wenn JavaScript nicht richtig lädt.
Lazy Loading ist eine weitere nützliche Technik, bei der Bilder oder andere Elemente erst bei Bedarf geladen werden, um den Pagespeed zu optimieren. Allerdings können Suchmaschinen per Lazy Loading geladene Inhalte möglicherweise nicht richtig indexieren. Achte daher auf Folgendes:
- Verwende das HTML-Attribut loading=“lazy“ für Bilder
- Verstecke Inhalte nicht mit display: none oder visibility: hidden
- Füge immer ein Platzhalterbild ein (z. B. src=“fallback.webp“)
Dadurch stellst Du sicher, dass Suchmaschinen schon vor dem Laden von JavaScript Deine Inhalte erfassen und verstehen.
Optimiere JavaScript für Performance und Nachhaltigkeit
Umfangreiche Skripte können Deine Seiten verlangsamen, was sowohl Deinen SEO-Bemühungen als auch der User Experience schadet. Gleichzeitig wächst auch Dein digitaler CO₂-Fußabdruck. Aber zum Glück gibt es Möglichkeiten, diese Auswirkungen möglichst gering zu halten:
- Ein guter Startpunkt ist die Minimierung und Komprimierung Deiner JavaScript-Dateien, um ihre Größe und Ladezeit möglichst gering zu halten. Viele Caching– und Optimierungstools minimieren automatisch den Code und ermöglichen GZIP-Komprimierung für schnelleren, schlanken Code. Im Internet findest Du auch Minimierungstools für jede andere Art von Code.
- Du kannst außerdem async und defer nutzen, damit andere Inhalte zuerst (also vor dem JS) geladen werden. Viele Optimierungs-Plugins sind ebenfalls dazu in der Lage.
- Zudem solltest Du sicherstellen, dass Dein JavaScript nicht das Rendering blockiert, denn das kann Deine Core Web Vitals beeinträchtigen.
Klingt kompliziert? Keine Sorge – in unserem Artikel zur Page Speed Optimierung erklären wir Dir im Detail, wie Du diese Schritte in der Praxis umsetzt.
Zusätzlich kannst Du mit den Chrome-Entwicklertools die “Abdeckung”, das heißt wie viel Code tatsächlich auf Deiner Seite verwendet wird, prüfen. So kannst Du nicht verwendete JS-Elemente finden, die Deinen Pagespeed unnötig verlangsamen.
Technisch versierte Nutzer können auch Code-Splitting in Betracht ziehen. Dabei werden größere Dateien oder JS-Bibliotheken in kleinere Teile aufgesplittet, die leichter zu handhaben sind und bei Bedarf geladen werden können.
Für Entwickler ist auch Vanilla JavaScript eine Überlegung wert, also JavaScript, das nicht auf bestehenden vorgefertigten Funktionen, sogenannten “Bibliotheken”, basiert. Alternativ könnte auch eine schlankere Bibliothek effizienter sein als Features, die von größeren Bibliotheken abhängig sind.
Achte auf JavaScript-Fehler und Crawlbarkeit
JavaScript-Fehler können Deine Seiten beschädigen und ihre Indexierung verhindern. Auf der technischen Seite können Dir die und die Chrome DevTools dabei helfen, Fehler zu finden und JavaScript zu debuggen.
Auch solltest Du darauf achten, dass Deine JS-basierten Inhalte von Crawlern korrekt gerendert werden. Allerdings kann es schwierig sein, selbst zu erkennen, was ein Crawler sehen wird. Mit dem URL Inspection Tool kann Dir die Google Search Console einige Hinweise liefern. Mit diesem Tool kannst Du jede einzelne Seite überprüfen, um sicherzustellen, dass sie von Google korrekt gerendert wird. Hier ein Beispiel:
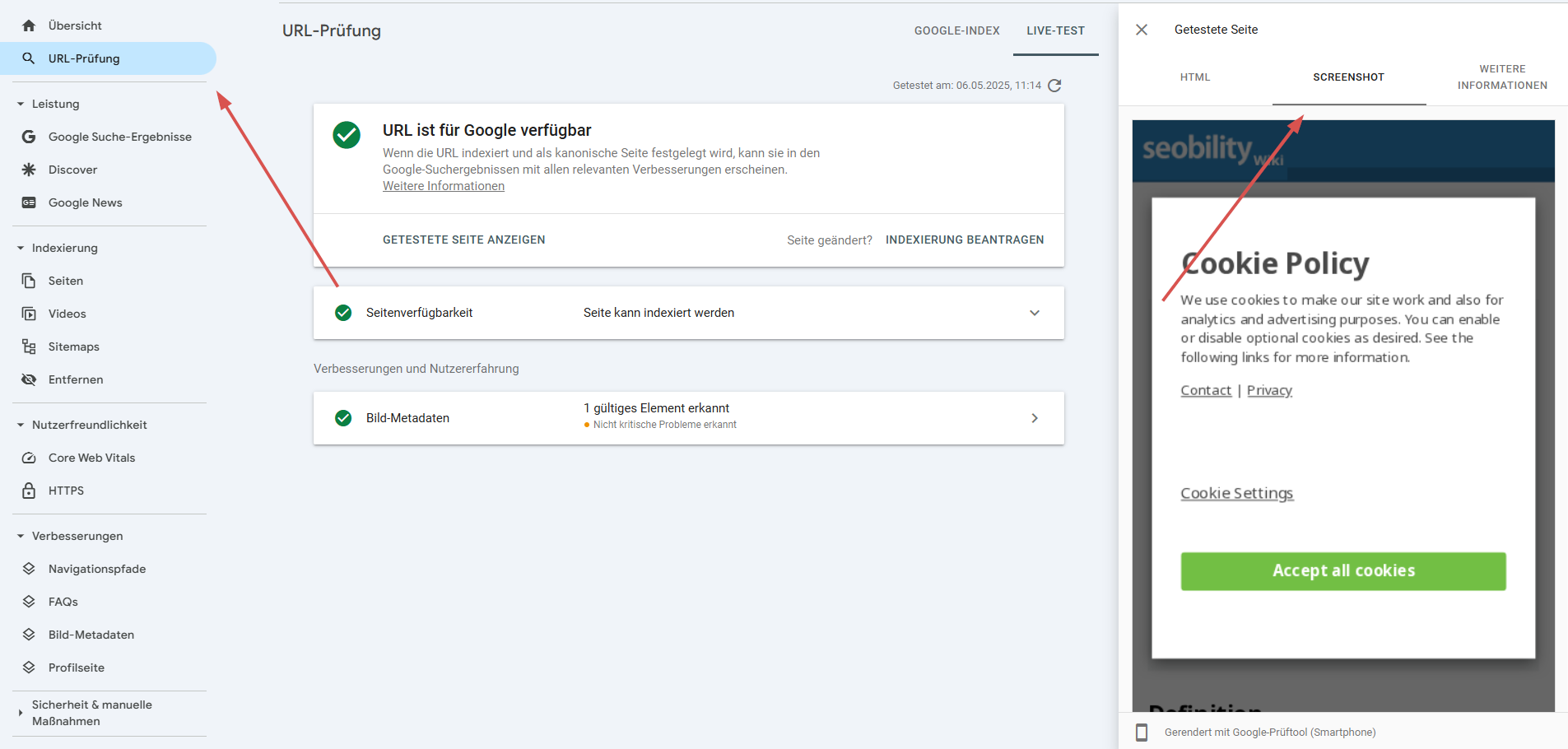
Manchmal sind jedoch detailliertere Informationen mit etwas mehr Kontext nötig. Und hier kommt Seobility ins Spiel! Unser Tool ist in der Lage, Websites mit dynamischen Inhalten, die über JavaScript bereitgestellt werden, zu crawlen.
Wie Seobility Dich in Sachen JavaScript SEO unterstützen kann
Das Seobility Website Audit bietet Dir zwei Crawling-Modi: den Standardmodus ohne JavaScript und den Chrome-Modus (mit aktiviertem JavaScript).
Zur Aktivierung des JavaScript-Crawlings gehst Du auf Übersicht > Crawlereinstellungen für Dein Projekt.
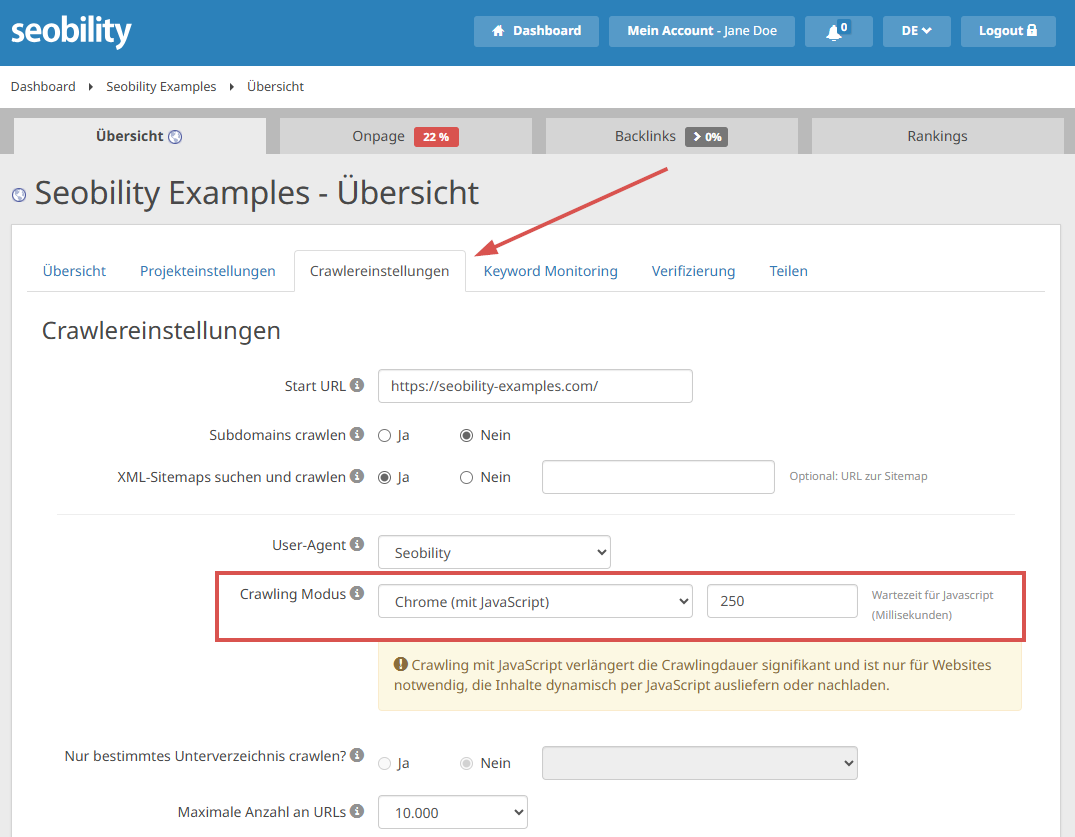
Der JavaScript-Crawling-Modus ist besonders bei JavaScript-lastigen Websites sinnvoll: Er ermöglicht die Analyse des gerenderten Codes anstatt nur des ursprünglichen HTML. So kannst Du besser erkennen, was JavaScript-fähige Suchmaschinen in der Realität sehen, obwohl es immer noch keine Garantie ist.
Du kannst auch die JavaScript-Wartezeit festlegen, um so die „Geduld“ der Crawler zu simulieren. So siehst Du genau, was Suchmaschinen möglicherweise erkennen oder nicht erkennen.
Bitte beachte dabei, dass JavaScript-Crawlings deutlich länger dauern als reguläre HTML-basierte Crawlings.
Der Report zu eingebundenen Dateien, den Du unter Onpage > Technik & Meta findest, kann ebenfalls nützliche Einblicke liefern und Probleme mit Deinen JavaScript-Dateien aufzeigen.
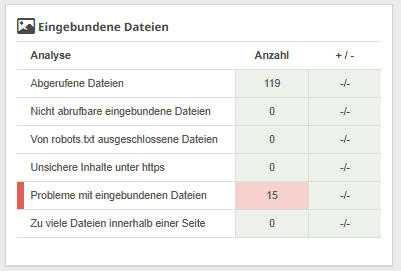
Dieser Bericht hebt alle Probleme im Zusammenhang mit Dateien hervor, die auf Deiner Website verwendet werden, einschließlich JavaScript-Dateien. Zum Beispiel, wenn es einfach zu viele JavaScript-Dateien gibt oder diese Dateien groß sind und die Performance beeinträchtigen.
JavaScript-Probleme können sich in der Seobility-Analyse aber auch auf andere Weise zeigen:
- Fehlende Metadaten, Alt-Attribute oder etwas anderes, bei dem Du Dir sicher warst, es berücksichtigt zu haben? – Das kann passieren, wenn über JavaScript Bilder oder wichtige Inhalte eingefügt werden.
- Nicht erkannte Lazy-Loaded-Bilder? – Für wichtige Bilder sollte kein Lazy Loading verwendet werden, da sie sonst leicht von Crawlern (ja, auch vom Seobility Crawler) übersehen werden können.
- Zu viele JavaScript-Dateien, aber Du wusstest bisher nichts von ihrer Existenz? – Klicke auf “Details” im entsprechenden Report, um die URLs direkt ausfindig zu machen.
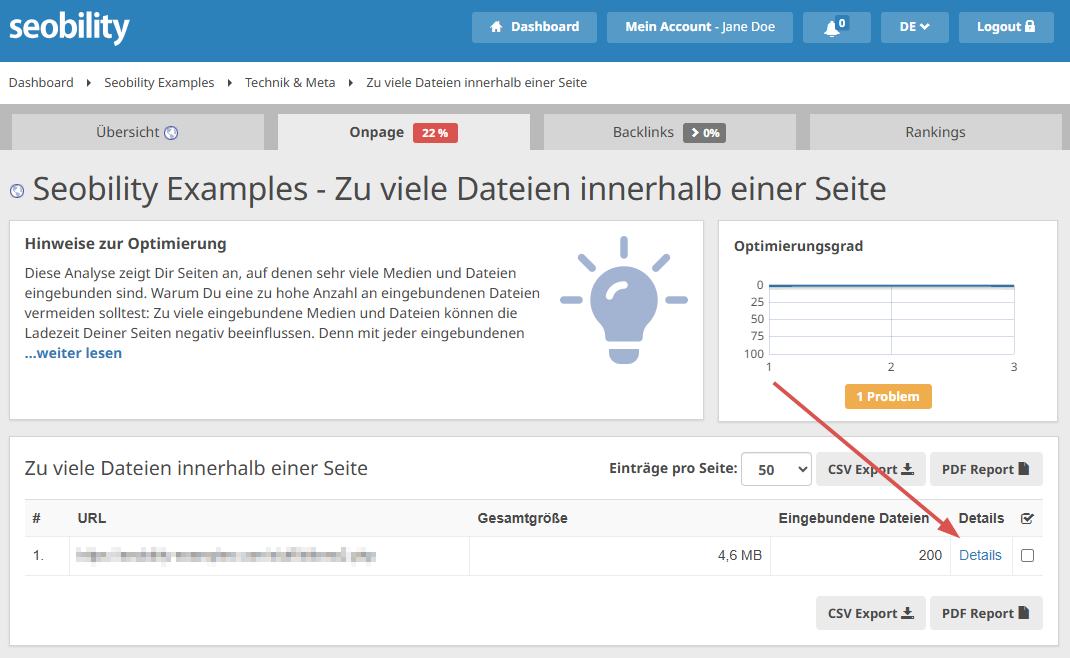
Du kannst Seobility auch so einrichten, dass Deine Website regelmäßig neu gecrawlt wird:
Übersicht > Projekteinstellungen
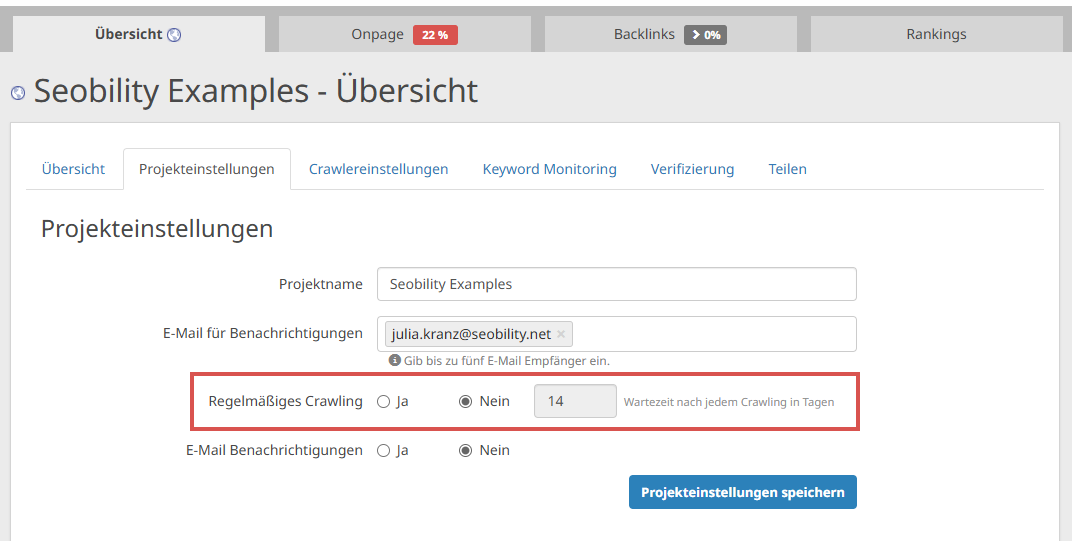
So kannst Du immer Deine Fortschritte bei der Optimierung Deiner JavaScript-haltigen Website verfolgen – oder schnell eingreifen, wenn etwas schiefläuft!
JavaScript & SEO: Nicht zwangsläufig ein Widerspruch
Ja, dynamische Inhalte, die per JavaScript eingefügt werden, stellen einige Herausforderungen für die Optimierung dar und beeinflussen die Art und Weise, wie Suchmaschinen Inhalte crawlen, rendern und indexieren. Doch mit Best Practices wie Server-Side Rendering (SSR), Progressive Enhancement, Lazy Loading, die Optimierung Deines JavaScripts und der gründlichen, regelmäßigen Überprüfung auf Fehler kannst Du optimieren, wie Deine Inhalte von Suchmaschinen verarbeitet werden.
Während die generelle Minimierung von JavaScript und dynamischen Inhalten Dir wahrscheinlich Kopfschmerzen (und CO₂) ersparen wird, gelten viele dieser Best Practices für mehr als nur JavaScript. Und lass Dich nicht von den kniffligen Details abschrecken: JavaScript ist nahezu unverzichtbar, wenn Du eine reaktionsschnelle, zugängliche User Experience schaffen möchtest. Und die Optimierung für Suchmaschinen ist durchaus möglich.
Probiere jetzt das JavaScript Crawling mit Seobility aus – hier kannst Du unser Tool 14 Tage kostenlos testen!
Lust auf mehr JavaScript?
- Google: Grundlagen von JavaScript-SEO
- Seobility Wiki: JavaScript
- SEOSLY Podcast auf YouTube: JavaScript SEO in 2024 Q&A mit Martin Splitt von Google (Probleme, Fehler, Tipps, Fakten & Mythen)




