
Definition

TF*IDF is a formula for calculating the weighting of certain terms in a document in relation to the total number of documents dealing with the same subject. The formula can also be applied in the context of web pages. In this case, it denotes the weighting of certain terms on a web page in relation to all other pages that rank for a specific search term.
Using the TF*IDF formula, you can analyze textual content on your website and compare it to other web pages in order to increase the relevance of your content for a particular search term. For this reason, optimizing your content according to TF*IDF is an important task in search engine optimization (SEO).
TF*IDF Analysis
Check the TF*IDF optimization of any URL for any keyword
Calculation
Two formulas are required to calculate the TF*IDF value: TF and IDF.
TF
TF stands for “Term Frequency” and serves to calculate the frequency of a term, i.e. a single word or a certain word combination, in a document or on a web page in relation to all other terms on this page. The corresponding formula is:
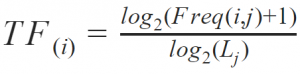
Freq(i,j) = Frequency of term i in document j
L(j) = Total number of terms in document j
Basically, this is the keyword density, with the only difference that the values are logarithmized. The logarithmic function serves to “compress” the results, i.e. it prevents particularly high term frequencies from distorting the value.
IDF
IDF is the abbreviation for “Inverse Document Frequency“. This value stands for the number of all considered documents in relation to the number of documents that contain the term i. The corresponding formula is:

ND = Number of considered documents
fi = Number of documents containing term i
The lower the number of documents containing term i, the higher the IDF and the more important the term. This can be explained by the fact that rare words and expressions are more informative for classifying the content of a document than terms that are present in almost all documents. Due to the higher significance of rare words (represented by a high IDF value), multiplication by TF results in a higher overall value.
Multiplication of TF and IDF
The multiplication of both individual frequencies yields the relative term weighting of a word in a document in relation to all documents considered. Terms that occur frequently in a document but are rather rare in all other documents have a high TF*IDF value. An example would be the term “SEO” in a text about search engine optimization.
However, if a term occurs frequently in a document, but is also mentioned very often in all other documents, its TF*IDF value is low. This is the case for words such as “and”, “the”, “with”, etc. These terms contribute very little to classifying the content of a document.
Importance for SEO
Using the TF*IDF formula, you can compare the content on your website with the content of the best ranking pages to a keyword. Such a comparison can reveal important optimization potentials for your content and is possible with Seobility’s TF*IDF tool, for example. TF*IDF tools indicate which terms should appear more or less frequently in a text to achieve an optimal ratio. In addition, so-called “proof keywords” can be used to underline the relevance of your texts for a specific search term. These are expressions that are semantically close to the considered search term and proof that your text is about that topic. Documents that exceed the average term weighting, are sometimes considered spam. Reducing the frequency of said terms helps to avoid such misinterpretation.
In addition, TF*IDF tools can serve as inspiration when searching for specific sub-topics that should be addressed in a text about a specific search term.
Screenshot with exemplary TF*IDF analysis for the term “SEO” of seobility.net
Overall, TF*IDF offers a better possibility to optimize your content compared to keyword density and has replaced it by now. Therefore, it is an important element of on-page optimization that can contribute to better rankings.
Disadvantages
Despite the high importance of TF*IDF for content optimization, the formula also has disadvantages.
For example, the TF*IDF comparison is more suitable for texts that are displayed as results for the search intent “Information” on Google. For other content, such as product descriptions in online shops, optimization according to TF*IDF makes little sense.
Another disadvantage is that TF*IDF tools need to know or estimate the total number of documents in order to deliver meaningful results.
Furthermore, aspects such as synonyms or the distribution of terms in a text, which are also important for the semantic classification of documents, are not considered in the TF*IDF formula.
You shouldn’t focus on TF*IDF too much when optimizing your content, because a good text is not only characterized by the weighting of certain terms. Factors such as linguistic quality, reading flow or emotionalization are also of great importance. The strict implementation of term frequencies, on the other hand, can lead to a loss of readability and text quality.
You should also bear in mind that the SERPs change frequently and therefore all texts would have to be re-analyzed and adapted in the event of a change. For this reason, TF*IDF optimization should focus on the most important terms instead of writing over-optimized texts that need to be updated regularly.
Despite the many advantages of TF*IDF, you should always remember that this is just one of many elements of onpage optimization. The formula is not a panacea for your website and can’t compensate a bad backlink profile etc.
Related links
Similar articles
