GET-Parameter: Unterschied zwischen den Versionen
| Zeile 2: | Zeile 2: | ||
== Definition == | == Definition == | ||
| − | + | [[File:GET-Parameter.png|mini|450px|rechts|alt=GET-Parameter|'''Abbildung:''' GET-Parameter - Autor: Seobility - Lizenz: [[Creative Commons Lizenz BY-SA 4.0|CC BY-SA 4.0]]|link=https://www.seobility.net/de/wiki/images/5/52/GET-Parameter.png]] | |
GET-Parameter (auch: URL-Parameter) werden genutzt, wenn ein Client, zum Beispiel ein Browser, mittels HTTP-Protokoll eine bestimmte Ressource von einem Webserver anfordert. Anhand der GET-Parameter wird die angeforderte Ressource definiert. GET Parameter sind immer Name-Wert-Paare. | GET-Parameter (auch: URL-Parameter) werden genutzt, wenn ein Client, zum Beispiel ein Browser, mittels HTTP-Protokoll eine bestimmte Ressource von einem Webserver anfordert. Anhand der GET-Parameter wird die angeforderte Ressource definiert. GET Parameter sind immer Name-Wert-Paare. | ||
Version vom 1. September 2020, 16:42 Uhr
Inhaltsverzeichnis
Definition
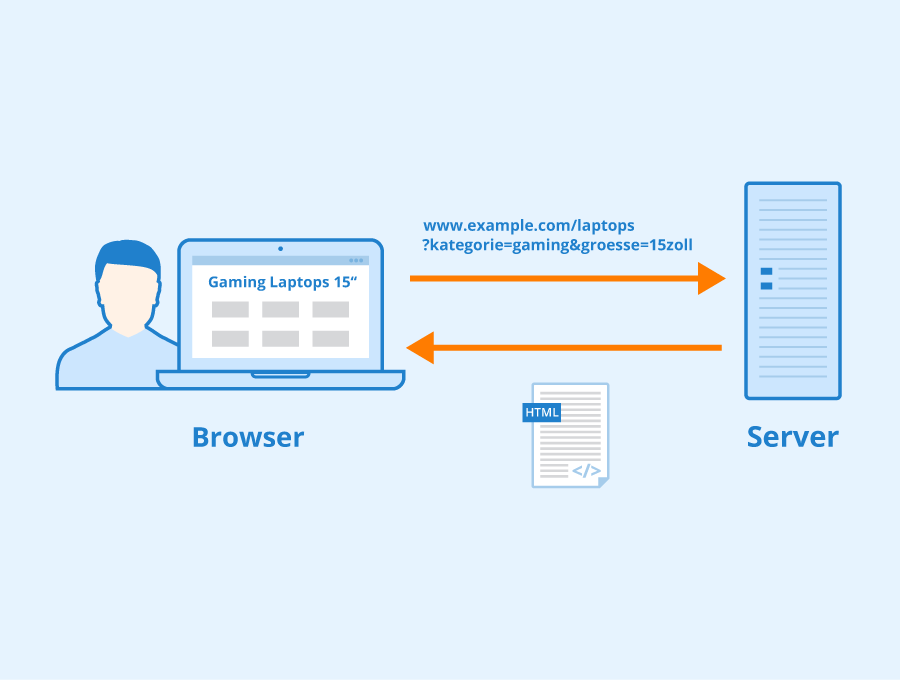
GET-Parameter (auch: URL-Parameter) werden genutzt, wenn ein Client, zum Beispiel ein Browser, mittels HTTP-Protokoll eine bestimmte Ressource von einem Webserver anfordert. Anhand der GET-Parameter wird die angeforderte Ressource definiert. GET Parameter sind immer Name-Wert-Paare.
Funktionsweise der GET Anfrage
HTTP funktioniert als Anfrage-Antwort-Protokoll zwischen einem Client und einem Server. Insgesamt sind 9 verschiedene Anforderungsmethoden in HTTP definiert, um die gewünschte Aktion anzugeben, die für eine bestimmte Ressource vom Server ausgeführt werden soll. Jede dieser Anforderungsmethoden implementiert eine andere Semantik. Die GET Anfrage ist eine der gebräuchlichsten HTTP-Request-Methoden.
Eine GET Anfrage wird verwendet, um Daten von einer angegebenen Ressource anzufordern. Ein Client, zum Beispiel ein Browser kann diese HTTP Methode verwenden, um eine Webressource von einem Server abzurufen. Mit der GET Anfrage werden vom Client zusammen mit der angefragten URL die GET-Parameter übermittelt. GET-Parameter sind immer Name-Wert-Paare. Die Name-Wert-Paare werden mit einem "?" an die URL angefügt. Der Name und der zugehörige Wert werden immer durch ein "=" voneinander getrennt.
Eine GET Anfrage hat folgende beispielhafte Syntax:
https://www.example.com/index.html?name1=value1
Mit einer GET Anfrage können aber auch mehrere Parameter übermittelt werden. Die Länge der Anfrage und damit die Anzahl der übermittelten Name-Wert-Paare ist nur durch die maximal mögliche Länge einer URL begrenzt. Bei der Übermittlung mehrerer Parameter werden die einzelnen Parameter durch das kaufmännische UND-Zeichen ("&") voneinander getrennt. Werden beispielsweise mehrere Parameter bei der Verwendung der Filterfunktion eines Onlineshops übergeben, kann die GET Anfrage wie folgt aussehen:
https://www.example.com/index.html?Kategorie=Mountainbikes&Groesse=29_Zoll&Farbe=Orange
Die Antwort des Servers auf eine Anfrage eines Clients enthält Informationen darüber, ob die angeforderte Ressource auf dem Server vorhanden ist und wo der Client die Ressource finden kann. Die Antwort enthält somit nicht direkt die angeforderte Ressource. Der Browser kann die Ressource jedoch im Anschluss anhand der vom Server erhaltenen Informationen laden und anzeigen. Der Grund für diese wechselseitigen Anfragen und Antworten zwischen Client und Server liegt darin, dass das HTTP-Protokoll auf eine Frage nur eine Antwort erlaubt.
Die Eigenschaften von GET-Anfragen
GET-Anfragen können grundsätzlich zwischengespeichert und mit einem Lesezeichen versehen werden. Zudem verbleiben sie im Browserverlauf. Aus diesem Grund sollte diese HTTP-Anfragemethode nicht im Umgang mit sensiblen Daten, wie zum Beispiel Login-Informationen, verwendet werden.
Weiterhin werden mit einer GET-Anfrage nur Daten angefordert und keine Ressourcen verändert. Daher wird davon ausgegangen, dass es sich um eine sichere, wiederholbare Operation von Browsern, Caches und anderen HTTP-fähigen Komponenten handelt. Dies bedeutet, dass GET-Anfragen ohne vorherige Prüfung erneut ausgegeben werden können. So hat beispielsweise die Anzeige des Kontoguthabens, die mit einer GET-Anfrage realisiert wird, keinen Einfluss auf das Konto und kann daher sicher wiederholt werden. Aus diesem Grund ermöglichen es Browser einem Benutzer, eine Seite zu aktualisieren, die aus einer GET-Anfrage resultiert, ohne eine Warnung anzuzeigen. Auch andere HTTP-fähige Komponenten wie Proxys können GET-Anforderungen automatisch erneut übermitteln, wenn sie auf ein temporäres Netzwerkverbindungsproblem stoßen.
Ein Nachteil von GET-Anforderungen besteht allerdings darin, dass sie nur Daten in Form von Parametern bereitstellen können, die im URI oder als Cookies im Cookieanforderungsheader codiert sind. Daher kann diese Methode nicht zum Hochladen von Dateien oder für andere Vorgänge verwendet werden, bei denen große Datenmengen an den Server gesendet werden müssen.
GET-Parameter und Duplicate-Content
Die Generierung der GET-Parameter, beispielsweise auf Basis der Einstellungen von Website-Filtern, kann schwerwiegende Duplicate Content Probleme bei E-Commerce-Seiten verursachen. Denn wenn Shopbesucher Filter verwenden können, um den Inhalt einer Seite zu sortieren oder einzugrenzen, werden zusätzliche URLs generiert, obwohl sich die Inhalte der Seiten nicht zwangsläufig unterscheiden. Zur Veranschaulichung dieses Problems soll folgendes Beispiel dienen:
Wenn die URL einer E-Commerce-Website die vollständige Liste aller vorhandenen Produkte in aufsteigender alphabetischer Reihenfolge enthält und der Benutzer die Produkte in absteigender Reihenfolge sortiert, ist die URL für die neue Sortierung /all-products.html?sort=Z-A. In diesem Fall hat die neue URL den gleichen Inhalt wie die ursprüngliche Seite, nur in einer anderen Reihenfolge. Dies ist allerdings problematisch, da diese Inhalte von Google als Duplicate Content gewertet werden können. Die Folge ist, dass Google nicht bestimmen kann, welche Seite in den Suchergebnissen angezeigt werden soll und welche Rankingsignale welcher der URLs zugeordnet werden sollen, wodurch sich die Relevanz auf die beiden Unterseiten aufteilt.
Eine Lösung dieses Problems besteht darin, die Beziehung der Seiten zueinander eindeutig durch Canonical-Tags zu definieren.
Canonical-Tags werden verwendet, um Suchmaschinen anzuzeigen, dass bestimmte Seiten als Kopien einer bestimmten URL behandelt werden sollen und dass alle Rankings tatsächlich der kanonischen URL gutgeschrieben werden sollten. Ein Canonical Tag kann im <head>-Bereich des HTML-Dokuments oder alternativ in den HTTP-Header der Webseite eingefügt werden. Wird der Canonical Tag im <head>-Bereich implementiert lautet die Syntax beispielsweise:
<link rel="canonical" href="https://www.example.com/all-products.html"/>
Wird dieser Link allen URLs, die durch unterschiedliche Kombinationen von Filtern entstehen können, hinzugefügt, wird die Link Power all dieser Unterseiten auf die kanonische URL gebündelt und Google weiß, welche Seite in den SERPs angezeigt werden soll.
Der Canonical Tag ist somit eine einfache Lösung, um Suchmaschinen Crawler zu dem Inhalt zu führen, den sie indexieren sollen.
Eine weitere Möglichkeit, um Duplicate Content durch GET-Parameter zu vermeiden, ist die zusätzliche Angabe der kanonischen URLs in einer Sitemap.
Grundsätzlich kann Duplicate Content Problemen vorgebeugt werden, indem überflüssige Parameter in einer URL vermieden werden. Das erhöht gleichzeitig die Usability, da die URL durch die Aneinanderreihung der GET Parameter für User unleserlich und schwer verständlich wird.